Coping With The AI Workflow
Published Apr 12, 2021
I will use the freedom of writing that a blog post can provide, to warn potential readers that the following content will strictly express my personal view on this topic. You might find my approach of writing unusual, as this software technology-related article is not a typical one and it won’t include any code snippets, numbers or concise paragraphs.
Instead, I am going to provide my own personal experience and views on several projects which have integrated some aspects of Artificial Intelligence. By AI I am referring to the most broader possible field encompassing Machine Learning, Data Science, Robotics and so on, even though the tendency these days is to use some of these subfields instead.
For the past two decades, I’ve been a part of several projects and research activities that tackled various AI aspects, ranging from basic string processing when most of the algorithms had to be created from scratch to a language and speech generation using a variety of software with already built-in algorithms. And for the most part, due to these frequent changes in the AI world, I’ve found myself in challenging situations.
Some were caused by the difficulties to recognize and use standard working methodologies. Others were the result of the “dry” periods when my mind was occupied with other projects that resulted in having a hard time filling out the knowledge “gaps”. However, the harsh experience combined with many hours of “unnecessary” development work made me value the importance of establishing the AI standards and the technical revolution in cloud computing.
For that reason in the following article, I will try and link all those past moments with the current challenges that one, no matter whether it’s an individual, a team or an institution, can experience while working on an AI project.
Let’s begin. The question is how?
AI has been the hype for several decades now. However, those who start working on developing such solutions but at the same time lack the experience are not really aware of the struggle they might encounter along the way. Also, they often don’t have a plan on how to begin, even though there are several options to consider, some of which can be to:
- focus only on the business requirements and let another subject deal with the solution;
- refer to another more experienced subject and use its consultancy services for in-house development;
- upscale its own knowledge, conduct research that will be put to good use for every upcoming project.
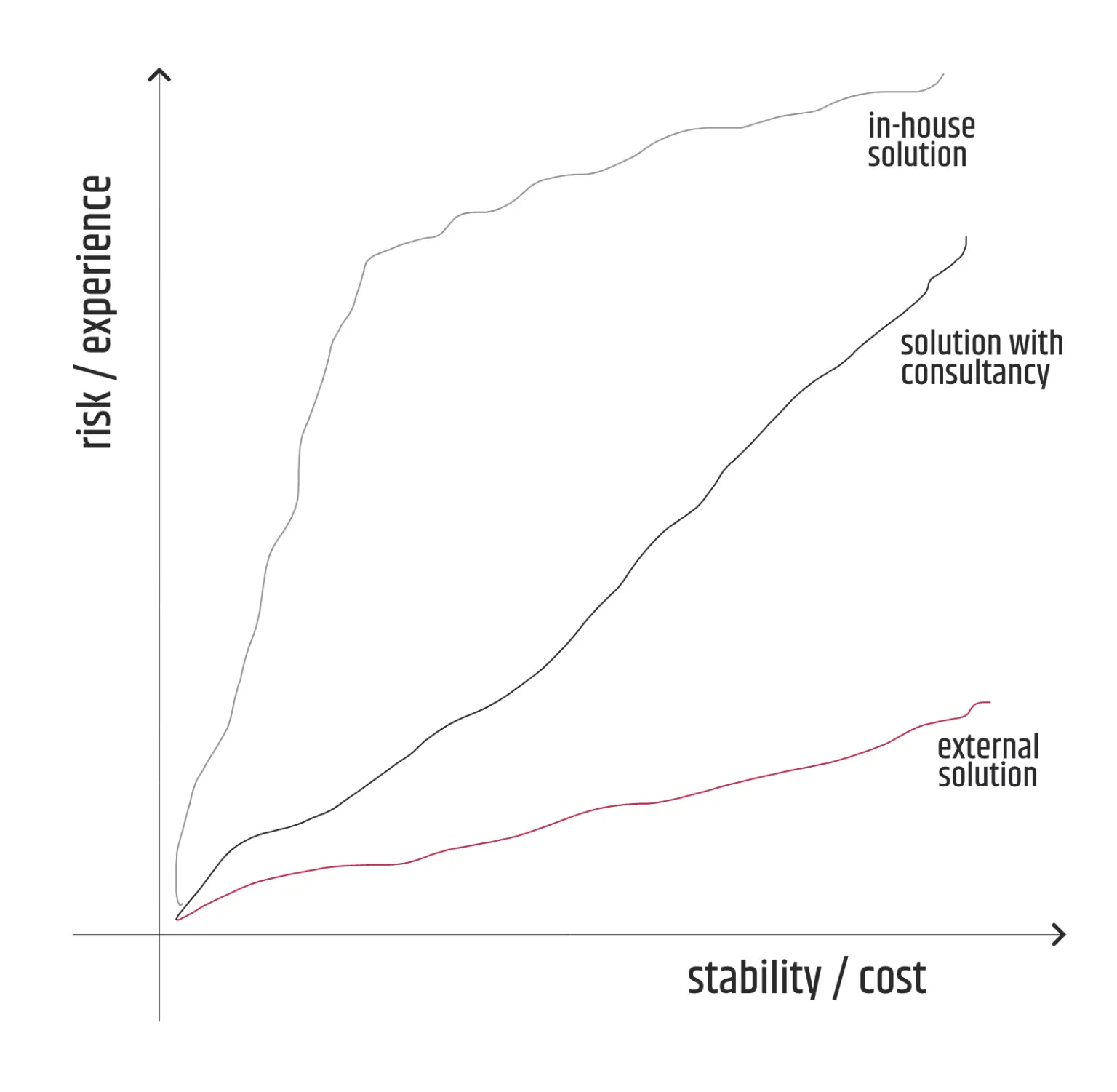
Understandably, the first option is often costlier, but at the same time, it minimizes the risk of not delivering or delivering an unsuccessful solution. However, if the solution turns out to be completely unsuccessful, the subject initiator is left almost completely empty-handed, aside from the bad experience it encountered.
On the other hand, the third option can be a huge risk, but even if the outcome of the project is doomed, the benefits of the investment, especially in knowledge and experience, definitely stay and can be used for the next similar projects. Therefore as a long-term approach, it is far more promising than the first one and I recommend it to be followed in general, along with the second option unless it is too biased by the consultancy services.
Gathering resources
When I say resources, I refer mainly to people and technology. Even with the latest software advances, it is hard to work on an AI project as a single. You need to organize at least a small team of individuals that have to satisfy the minimum required capacity and are motivated to work hard. The latter is especially true because building an AI solution can be hard, long and unusual, and it’s something that an ordinary engineer is not usually accustomed to.
Often, to release a “smart” solution or to increase accuracy, the dedicated tasks can be quite repetitive. So there might be an “effect” of demotivation or unwillingness to raise the level of contribution that can strike any team member at any time.
When it comes to the technologies used, compared to the software quantity/quality available two decades ago, the situation has improved drastically. There are “tons” of extremely useful languages, platforms, frameworks, libraries, tools and on top of that, cloud services, with extended documentation, learning materials/courses and examples. This means that today even an intermediate engineer has a better opportunity to learn how to use the software in practice.
After this, it’s natural to answer the question – do we need to establish a team consisting of individuals with specific job positions for the project purposes? Or to rephrase the question, why not generalists over specialists?
Of course, it’s nice to have a certified ML engineer or a data analyst with multiple years of experience, but it is not a condition to be strongly met. And in reality, it is hard to be met because the availability pool is not that big.
For example, when it comes to the development part, it’s enough to find engineers with the right mindset and experience in at least one of the top AI languages, which primarily “translates” to Python or Java and Javascript which are not far behind, who can adjust to the working principles which are different than the standard project development.
What about the principles of work?
In general, there is a difference in the approach when you deal with an AI project. It is definitely a unique possibility but more or less the AI solution delivers an “intelligence” that does something “smart” either as a “mirror” of human behavior or something a natural intelligence can never do by itself.
Before we dive into the AI project’s specifics, I need to mention one important thing that not many are keen to pay attention to – the terminology. In this article, I will spare the reader of using fancy words and descriptions as much as I can. This, however, doesn’t mean that I’m afraid that I will be misunderstood, but I’m simply putting it out there since there are no precise standards or a clearly defined naming convention. In other words, the AI world lacks something that, for example, the WWW possesses – in the form of the W3C.
Over the years, I have also witnessed how AI terminology has changed. It hasn’t only evolved due to the new achievements, but it has become “refactored”, referring to the parts that haven’t changed their purpose. Primarily, the scientific institutions (mainly universities) were the facilitators, but in the past 15 years, the top cloud providers took over, making the battle of the standards a never-ending story, even though researchers like Geoffrey Hinton or Jeff Hawkins try and make compromises in their work.
Some of you may remember that when expressing the input variables the word column used to be more exploited than the word feature. Or another example is whether it is a label or an output class. Or why use the word hyperparameter instead of an argument? Something similar happens with the terms: prediction, inference, and generation, which are often prone to misusage.
You might ask, why am I putting so much focus on terminology?
Well, it’s very simple. When the project kicks off, the procedures such as meetings, documentation and any kind of communication suddenly become a must. There is a big chance that miscommunication will occur among the teammates. Therefore the first advice I would like to give to any team when establishing the principles of work is to align on the terminology even if it does not follow the (probably non-existing) standards, starting from the simplest (consts, vars) and ending with the more complex – the phases of the working pipeline.
The working pipeline should be included as well since it’s prone to changes and variants, even though currently one of the most popular methodologies serves as a basis for most of the pipelines out there. Including the ones that AI cloud service providers, such as AWS, recommend. On the other hand, every project is unique and can’t always be covered by those phases or in some cases, even the standard phases are not considered at all.
Therefore, my recommendation is to initially start with CRISP-DM methodology and apply minimal moves, introductions and removals of the phases or of the processes inside each phase. From my perspective, “the big three” can never be omitted:
- problem framing
- data preparation
- modeling
With all due respect to the data understanding, the evaluation of the deployment phases, some of their processes are flexible regarding their location in the pipeline.
For example, the data understanding is usually tightly coupled to the data discovery in the problem-framing phase. And the evaluation can be bound to the modeling or the deployment phase. The problem framing on the other hand can often be found as business understanding, even though it is only a process (the initial one) as part of that phase. Finally, the deployment phase can be skipped, especially for research projects or proof of concepts. Instead, you can use a more generalized usage phase.
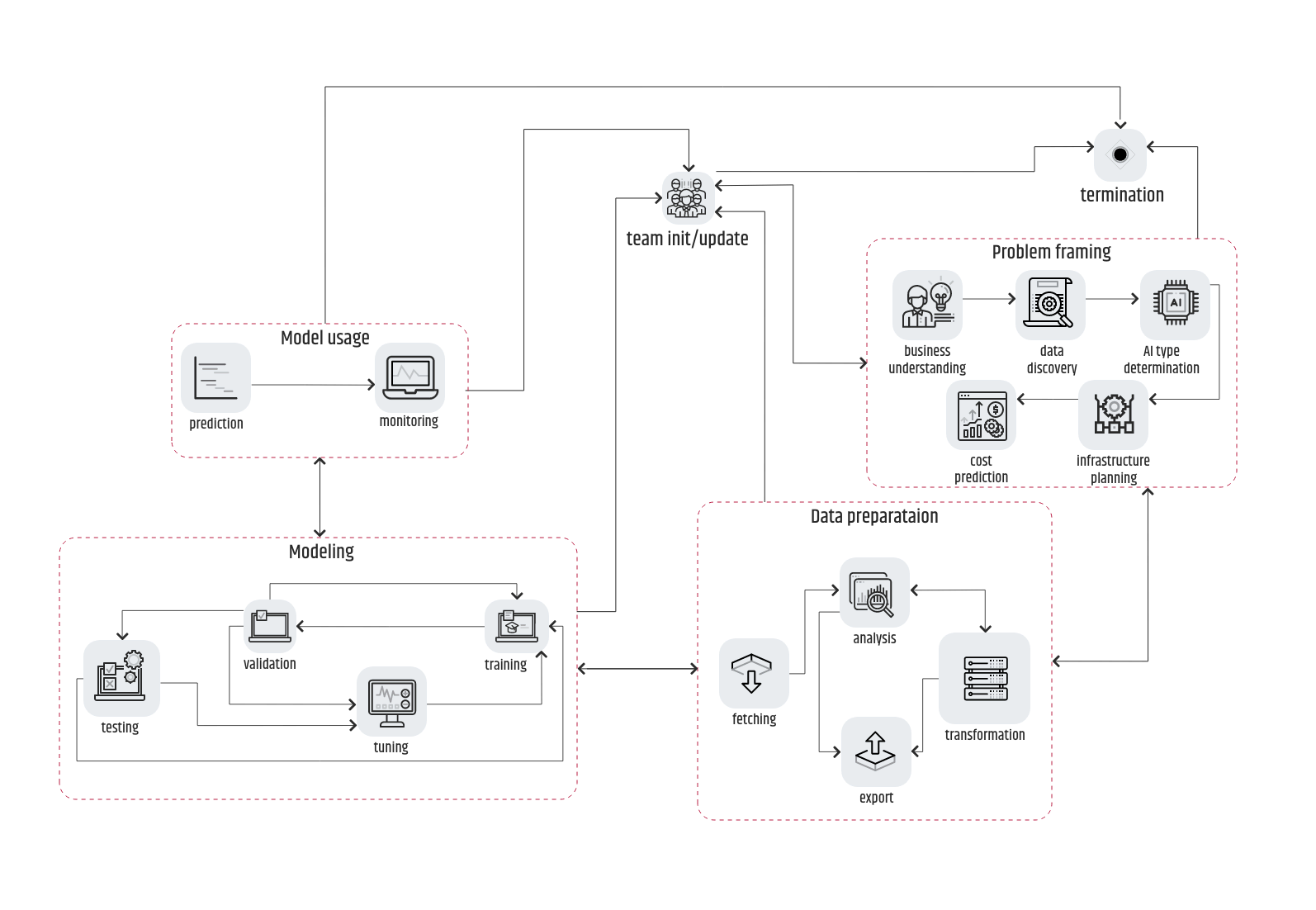
In the image above, it is shown that the arrows connecting each of the phases describing one variant of the CRISP-DM pipeline are bidirectional.
It means that even though the sequence will be problem framing -> data preparation -> modeling -> usage, there is always a reversal possibility. To help you understand easier, imagine that during the validation process there are slips that point to an inadequate training data set. That implies that data preparation “did not get the job done” as expected and has to be repeated. In the case of a “_Houston, we have a problem_” event, all team members need to be updated and either repeat the pipeline’s sequence from the beginning or in the worst-case scenario terminate the whole project.
As I mentioned in the intro there was a time when most of the AI-related algorithms had to be written from scratch simply because there was no external provider to help the developer. And because the outcome of the project depended on the quality of the algorithm, the focus was put on the successful determination of the AI type of the business problem. If anything went wrong, the recovery took much longer because the development of the replacement algorithm had to be done all over again.
Nowadays, with the availability of libraries and services that provide high-performance algorithms, covering almost anything from the complex graph traversal algorithms to the word2vec conversions, the AI type determination process lost the “throne” to the data preparation processes. Usually, even if the AI type is “wrong” and an inadequate algorithm is used, it can be easily replaced without (m)any changes to the training data set, meaning that often the subsequent processes will remain the same.
Once the work begins, it will take some time for an engineer to get used to the workflow. But after several iterations, the team will become more fluent and find the pipeline really useful for progress tracking. One obstacle that can remain is to find a way to integrate it into the development methodology that is already put into motion.
Can it be agile?
Before I start going into more details, let’s take a look at the possible ways to integrate the working pipeline into the accustomed methodology that a team or organization is not willing to sacrifice. Not willing to give up the proven methodology is not a bad thing at all, especially if it was successful previously. But striving to integrate a pipeline that seems unlikely to “fit” can be quite challenging.
Recently, you can find a lot of content about the concept of Agile Data Science on the internet. Most of the written articles come as a result of deep analyses but sometimes with contradictory summaries. However, I don’t intend to bother anyone with the conclusion points in those summaries. Instead, I will try and make several points that I believe are worth giving a chance.
If an AI project with a defined pipeline is considered to be integrated as part of a team’s everyday agile development, then the first impression is that this can be applied more effectively in the case of Kanban rather than Scrum.
In reality, again the choice depends on the flexibility of the resources – team + time. Let’s say we have an agile methodology of work i.e. a set of well-defined tasks and the details are as follows:
1. Firstly, we take risk factors into account and then we begin with task planning. However, for a research project or a proof of concept, this task planning can be disregarded. In order to satisfy the client, the product owner must be careful when promising a delivery because one cannot be 100% sure in which iteration of the pipeline it can occur. At the same time, the developer’s effort must not be increased drastically. Setting up milestones can help but at the same time, they should not be too specific. A bad example would be “release a model with 80% accuracy within a month” and a good example can be “release a functional model within a month”. The planning should represent a compromise between a product manager’s and a developer’s point of view. Of course, this cannot be applicable for R&D or proof of concept, where setting up deadlines should be avoided in order not to disrupt the research flow. That is unless the working intensity is not at a satisfying level.
2. There will be some situations when multiple tasks can be tackled at the same time. And although having an opportunity to parallelize your work that can potentially speed up the workflow, you have to keep an eye on the possible reversals when you start and finalize a task too soon. This scenario usually occurs when the requirements are related to a process that comes much later in the pipeline and the processes before have not yet been implemented. When the predecessor processes are ready, the old requirements can become obsolete and when that happens, the original task has to be repeated but this time with updated requirements. There can be two possible ways to resolve the setback of that scenario. First, to preserve the sequence of the tasks corresponding to the pipeline so that, for example, the transformation process (of the data set) is not released before the training. Second, the code units (scripts, modules, methods, …) have to be developed as generic as possible, structured properly and every opportunity to make them configurable should be grabbed so that frequent changes in the requirements of the same task do not cause significant development changes.
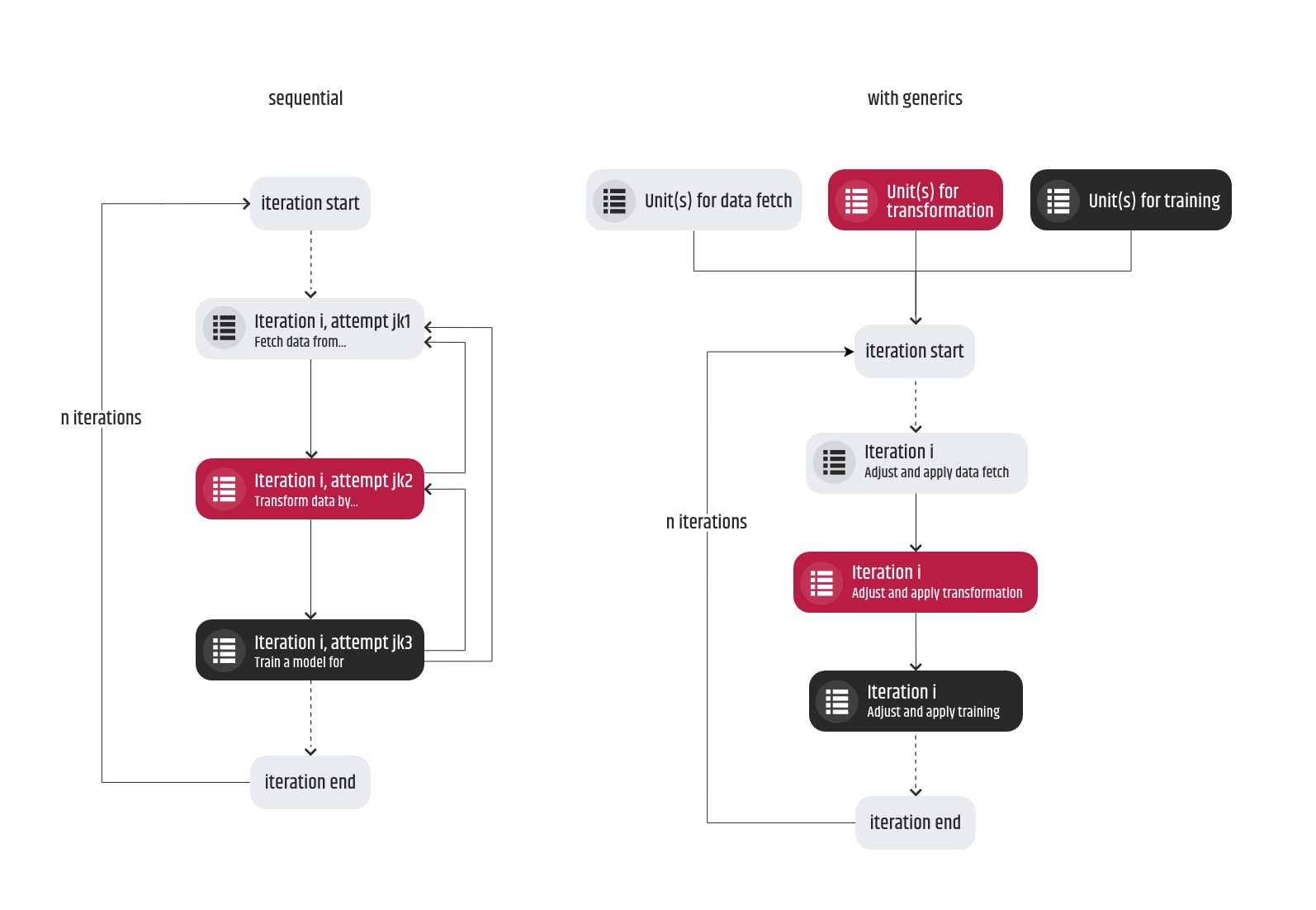
3. Multiple iterations of the same task are not uncommon and they should not pose a problem. Let’s say we have a task to train a model based on a data set prepared in one of the previous tasks. After its successful completion, the outcome is not satisfying. As a result, the next two tasks will come in a form of “prepare a data set for training in a different way” and “train a model based on the latest prepared data set” – so one quite similar and another almost the same but under different conditions.
4. I deliberately mentioned the training process because it is advisable to dedicate a separate task for a single training instead of including it as part of other tasks. By reducing the focus of the training, the main requirements of the task can result in an estimation issue.
5. A logging pattern should be established and applied during the first iteration of the pipeline. More precisely, when a process with any kind of output is developed, keeping logs about the desired metrics will help estimate the progress across multiple iterations. Introduction of the logging usually happens in the data preparation phase, after the data fetch process is finalized. It is important for the training, the validation, the testing and the processes in the usage phase. The logging should be performed per process. Over time, the logs can be expanded when certain explanatory gaps are detected. Analyzing and discussing the logs is essential for an overview of the actual performance on each training iteration and thus contributes to the estimation of the project’s success.
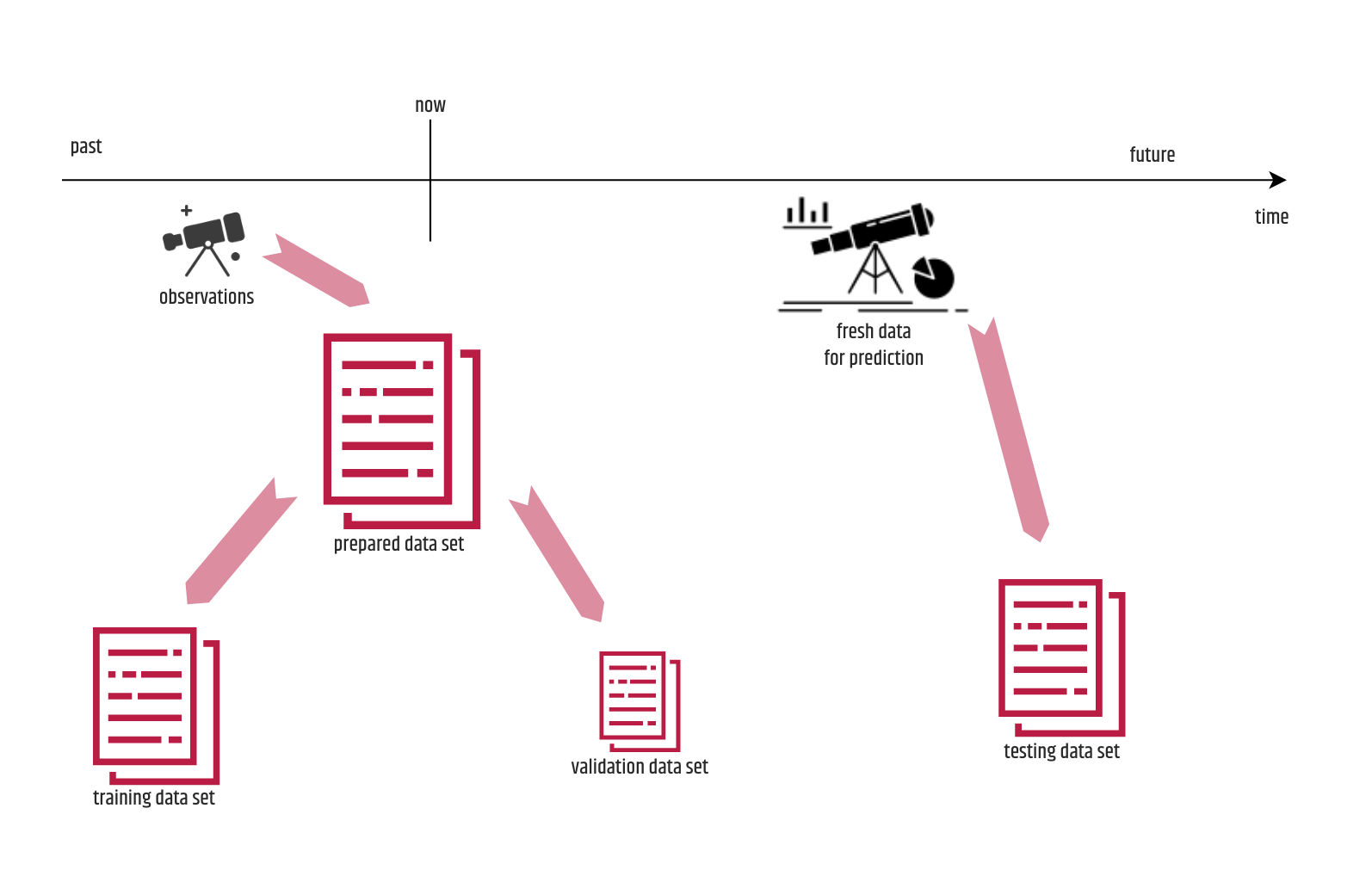
6. Try to establish a validation process immediately after the first iteration of the training process. Initially it will require some effort to implement it but later, in most scenarios it will save a lot of time either for manual validation or for unnecessary testing process. Besides using it for tuning, it can provide valuable information about the quality of the training and initiate team actions based on it. Many beginners usually consider validation as just another form of testing, which is not entirely true. The data set used for validation is a portion of the data set prepared for training but not effectively used for that purpose. That data consists of observations that occurred before the training, whereas the testing is performed by using so-called fresh data that is totally “unfamiliar” to the trained model. The train-validation-split rule stating that the portion of the prepared data set intended for validation should always be 15% is just a “myth” and the emphasis should be given on making the validation sample be large enough (not necessarily 15%), representative, containing different values for a feature and shuffled at the same time. As for expanding the validation it is preferable to split it in a number of tasks corresponding to the number of validation rules and gradually include them over time. In this way, you can easily track the impact that each of the rules had on the performance of the tuning.
7. Code review should be performed by as many people as possible. The reviewers do not necessarily need to be that much fluent in the programming language, because we “agreed” that we will gather a team of generalists. But by providing them a chance to see the code, they will learn the tricks and the purpose of the development related to a particular AI process and will have an increased chance of suggesting corrections compared to the conditions they face during the standard development.
8. Quality assurance of an AI task is highly recommended and developers should not play that role. I realize that testing a developed part of a process or a phase in an AI pipeline will require more effort than when a QA is performed on a simple development task. This has to cover not only the acceptance criteria but also to make sure that the changes will not disrupt the whole pipeline, with checking the logs along the way. Of course, this can represent a huge pain for the individuals who do the testing and maybe for the product managers who usually don’t like to stall the delivery because of “just another verification”. The truth is, performing a separate QA can enrich the output variants of the pipeline especially for the data preparation and the modeling phases.
And last, if the integration doesn’t work and you don’t agree with the provided details, the project can be developed using a different methodology but with a separate team, so that there are no blockers or interferences that will prolong the outcome.
In other words…
Even though I tried to adjust the expressions to make them suitable to an average reader, I realize it may not have been super understandable. Therefore I will rephrase and “compress” them in a short summary reflecting the main point(s) of this article.
I understand that there is a steep learning curve for every AI subfield and there will never be enough projects to work on so that you find it comfortable to say that you achieved expertise. But by all means don’t be afraid to use your own resources when considering an AI project, even if you feel that they are not sufficient.
There is a lot of evidence from the AI communities that generalists can make an impact as much as specialists. When you have trouble deciding how to start a project, you can always consider following the standard working methodology. If you find some process or maybe a whole phase not applicable, then you just disregard it, or else if you feel like you’re missing a node that is not in the usual diagrams, then feel free to introduce it, but tend to use the standard pipeline as your starting point.
Consequently, the quality outcome of the project should not be guaranteed on specific deadlines and that’s something a client is usually expected to understand. I’m very happy that Intertec is starting to think in the direction of offering its clients to take advantage of the data that they possess and use it for proposing a variety of AI solutions.
As for my fellow engineers, who are just getting started, obviously, I would like to “protect” them because realistically speaking, they are the most important cogs in the AI machinery. I know that at the end of the day, every developer makes a compromise under time or staff pressure, but if you are forced to do it, the tradeoff should be done in a way that does not disrupt the development process or the following of the aligned workflow. To build “something smart that does something smart” means potential for lightning-fast results and the road the engineers have to pass to get there can be long and bumpy. However, the satisfaction afterward is priceless.

Velimir Graorkoski
Software Engineer - AI



