Why Vector Stores Matter in Modern AI Systems
We are living through a fundamental shift in how machines understand data. For decades, search and retrieval meant matching keywords - find the exact string, return the exact row. That model worked well for structured, predictable data. However, large language models (LLMs) changed everything. They don't think in keywords. They think in meaning.
This is precisely why vector stores have moved from a niche data engineering topic to a must-have piece of modern AI infrastructure. They are the bridge between what users ask and what AI systems can meaningfully retrieve. Without them, even the most sophisticated LLM becomes forgetful and generic. With them, AI can reason over your proprietary data at production scale.
The numbers back this up. According to MarketsandMarkets, the global vector database market is projected to grow from $2.65 billion in 2025 to $8.95 billion by 2030—a CAGR of 27.5%. Meanwhile, Databricks' State of AI report found that vector databases supporting RAG applications grew 377% year-over-year—the fastest growth of any LLM-related technology category measured.
For CTOs building or scaling AI systems today, vector stores are infrastructure decisions. Not optional. Not experimental. Core.
What Is a Vector Store?
Vector Store Definition
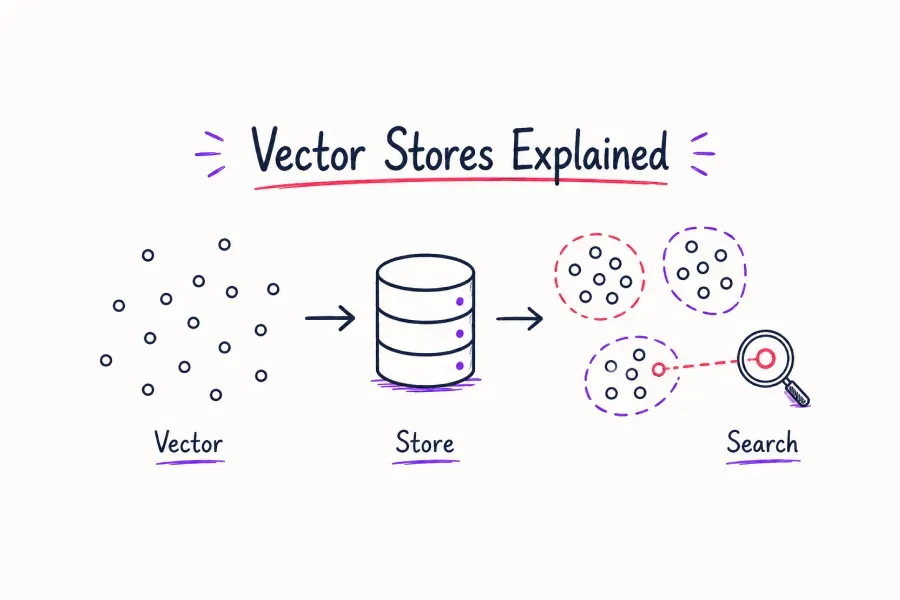
Put simply, a vector store is a specialized storage system designed to store, index, and search high-dimensional numerical representations of data called "embeddings." While commonly associated with AI, vector stores can serve any application that requires similarity-based retrieval over numerical representations. When you feed text, an image, audio, or a document into an embedding model (like OpenAI’s text-embedding-3-small, text-embedding-3-large or a Sentence Transformers model), the model converts it into a list of hundreds or thousands of floating-point numbers. That list is a vector, and it captures the semantic meaning of the original data.
For example, the sentences "I love my dog" and "My puppy makes me happy" will produce very similar vectors because they carry similar meaning. A traditional database would see two completely different strings with zero overlap. A vector store sees them as neighbors in high-dimensional space.
This is the core insight: vector stores enable similarity search, not exact-match search. That distinction matters enormously in AI applications.
How Does a Vector Database Work?
When data enters a vector store, it follows a specific pipeline. It is worth noting that a vector database is a step beyond a basic vector store, adding full database capabilities such as CRUD operations, indexing optimization, and query management on top of the core storage and retrieval functionality. Here is how it works:
Embedding generation - Raw data (text, image, or audio) is fed into an embedding model. The model outputs a fixed-length numerical vector, such as 3072 dimensions for OpenAI’s text-embedding-3-large model.
Indexing - The vector is stored alongside metadata and indexed for fast retrieval. Most vector stores use Approximate Nearest Neighbor (ANN) algorithms to do this efficiently at scale. HNSW (Hierarchical Navigable Small World graphs) is one of the most widely adopted indexing strategies.
Similarity search - At query time, the user's input is also converted to a vector. The database then searches for vectors close to the query vector using similarity metrics such as the following:
- Cosine similarity - Measures the angle between two vectors. Ideal for text embeddings.
- Euclidean distance - Measures the straight-line distance in vector space.
- Dot product - Fast, often used when vectors are normalized.
Ranked results - The database returns the closest matching vectors (and their associated content), ranked by similarity score.
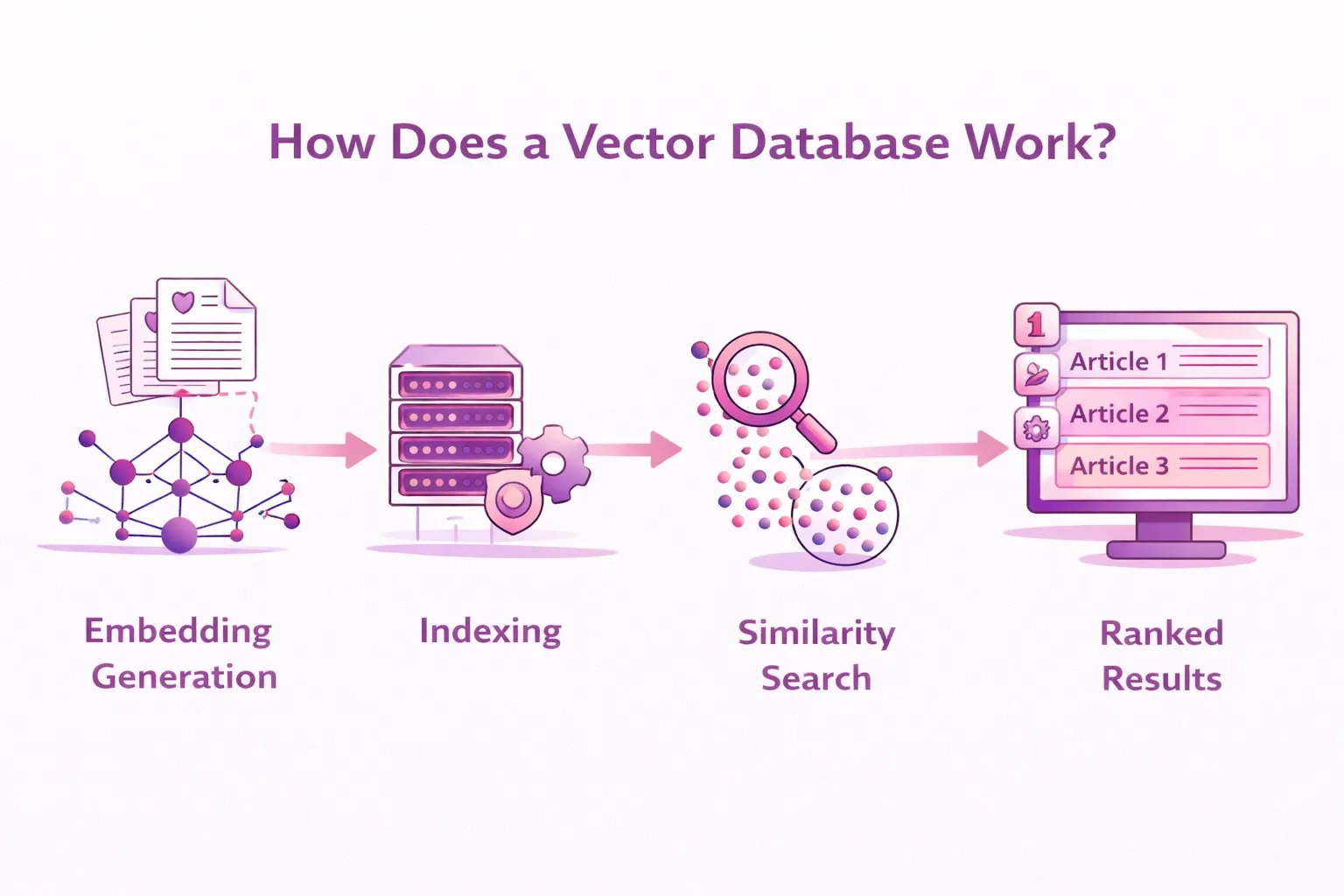
The full flow, from user query to ranked semantic results, typically completes in milliseconds at scale, which makes vector stores viable for production AI systems.
Vector Database vs Traditional Database
Key Structural Differences
To understand why vector stores exist, we need to understand what traditional databases are not built for.
| Feature | Traditional Database | Vector Database |
| Data model | Structured rows/columns | High-dimensional embeddings |
| Query type | Exact match (SQL) | Similarity search (ANN) |
| Schema | Rigid, predefined | Flexible, metadata-driven |
| Ideal workloads | OLTP, transactional | Semantic AI, retrieval |
| Scaling axis | Vertical (often) | Horizontal (distributed) |
Traditional databases answer questions like "Give me all users where age > 30 and city = 'Berlin.'" That is deterministic. Vector databases answer questions like "Which documents are most semantically similar to this query?" That is probabilistic. Both are valid. They solve fundamentally different problems.
When to Use Each Approach
The good news is you don't have to choose one or the other. In production AI systems, we almost always use both. Here's a practical way to think about it:
- Use a relational or document database for storing structured business data—customer records, transactions, and inventory.
- Use a vector store for semantic retrieval—matching user queries to relevant documents, knowledge base entries, or product descriptions.
- Combine them using metadata filtering in your vector store to narrow results before applying similarity search.
The vector database vs. traditional database debate is largely a false dichotomy. In mature AI architectures, they complement each other.
Types of Vector Databases
Not all vector stores are built the same way. When evaluating your options, it helps to understand the three main categories.
1. Native Vector Databases
These tools were built from the ground up for AI workloads. They prioritize high-speed similarity search, scalable indexing, and tight integration with embedding models and AI frameworks.
Examples include Pinecone, Qdrant, Weaviate, Milvus, and Chroma. FAISS (Facebook AI Similarity Search) also remains one of the most performant and easy-to-use vector stores, especially popular for local development and high-throughput search. These solutions typically offer the best raw retrieval performance, advanced filtering options, and support for complex indexing strategies like IVF-Flat and HNSW. However, they do require dedicated infrastructure and operational overhead.
2. Hybrid Databases with Vector Capabilities
These are traditional databases that have added vector search as a feature. PostgreSQL with the pgvector extension, MongoDB Atlas Vector Search, Redis Stack, and Elasticsearch's dense vector support all fall into this category.
The trade-off is straightforward: you get easier integration with existing infrastructure and a familiar operational model. However, you may sacrifice some performance at extreme scale, since these tools were not purpose-built for high-dimensional similarity search. For many enterprise use cases, the integration simplicity outweighs the performance delta.
3. Cloud-Managed Vector Services
These are fully managed vector database services offered by cloud providers. Amazon OpenSearch’s k-NN functionality, Azure AI Search with vector capabilities, and Google’s Vertex AI Vector Search all fall here. Additionally, AWS offers Amazon Bedrock Knowledge Bases, one of the most advanced and scalable approaches to semantic search in production. Bedrock handles the entire RAG workflow and supports multiple vector store backends including OpenSearch Serverless, Aurora PostgreSQL, and the recently launched Amazon S3 Vectors, which offers up to 90% cost savings for large-scale vector storage.
The advantages are obvious: no infrastructure to manage, built-in scaling, and tight integration with the broader cloud AI ecosystem. The trade-offs include potential vendor lock-in and higher per-query costs at significant scale. For teams that prioritize speed to production over cost optimization, cloud-managed options are often the right starting point.
Vector Stores in RAG Architecture
Role in RAG Architecture Components
Retrieval-Augmented Generation (RAG) is the dominant paradigm for deploying LLMs with custom, proprietary data. According to Menlo Ventures' 2024 State of Generative AI report, RAG now accounts for 51% of enterprise AI implementations, up from 31% the year before. Similarly, Databricks found that 70% of companies using LLMs leverage vector databases and retrieval systems to augment base models.
Vector stores are the beating heart of every RAG system. Here is how the pipeline works:
Data ingestion:
- Source documents (PDFs, wikis, databases) are chunked into segments of manageable size.
- Each chunk is passed through an embedding model to generate a vector.
- Vectors are stored in the vector store, indexed for fast retrieval.
Query-time retrieval:
- The same embedding model is applied to the user's query.
- The vector store performs similarity search and returns the top-k most relevant chunks.
- Those chunks are injected into the LLM's prompt as context.
- The LLM generates a response grounded in your actual data - not just its training.
This architecture solves one of the most critical problems in enterprise AI: keeping LLM responses accurate, current, and grounded in verified information.
Improving Data Retrieval Quality
The quality of your RAG system depends heavily on decisions made before a single user query arrives. Specifically:
- Chunking strategy: chunks that are too small lose context. Chunks that are too large introduce noise. Sentence-aware chunking or recursive character splitting typically outperforms naive fixed-size chunking.
- Metadata filtering: tagging chunks with metadata (date, document type, author, department)—allows pre-filtering before similarity search. This narrows the search space and improves relevance dramatically.
- Hybrid search: Combining dense vector search with sparse keyword search (BM25)—often produces better results than either approach alone. This technique captures both semantic relevance and exact keyword matches.
- Re-ranking models: After initial retrieval, a cross-encoder model can re-score and reorder results for higher precision before they reach the LLM.
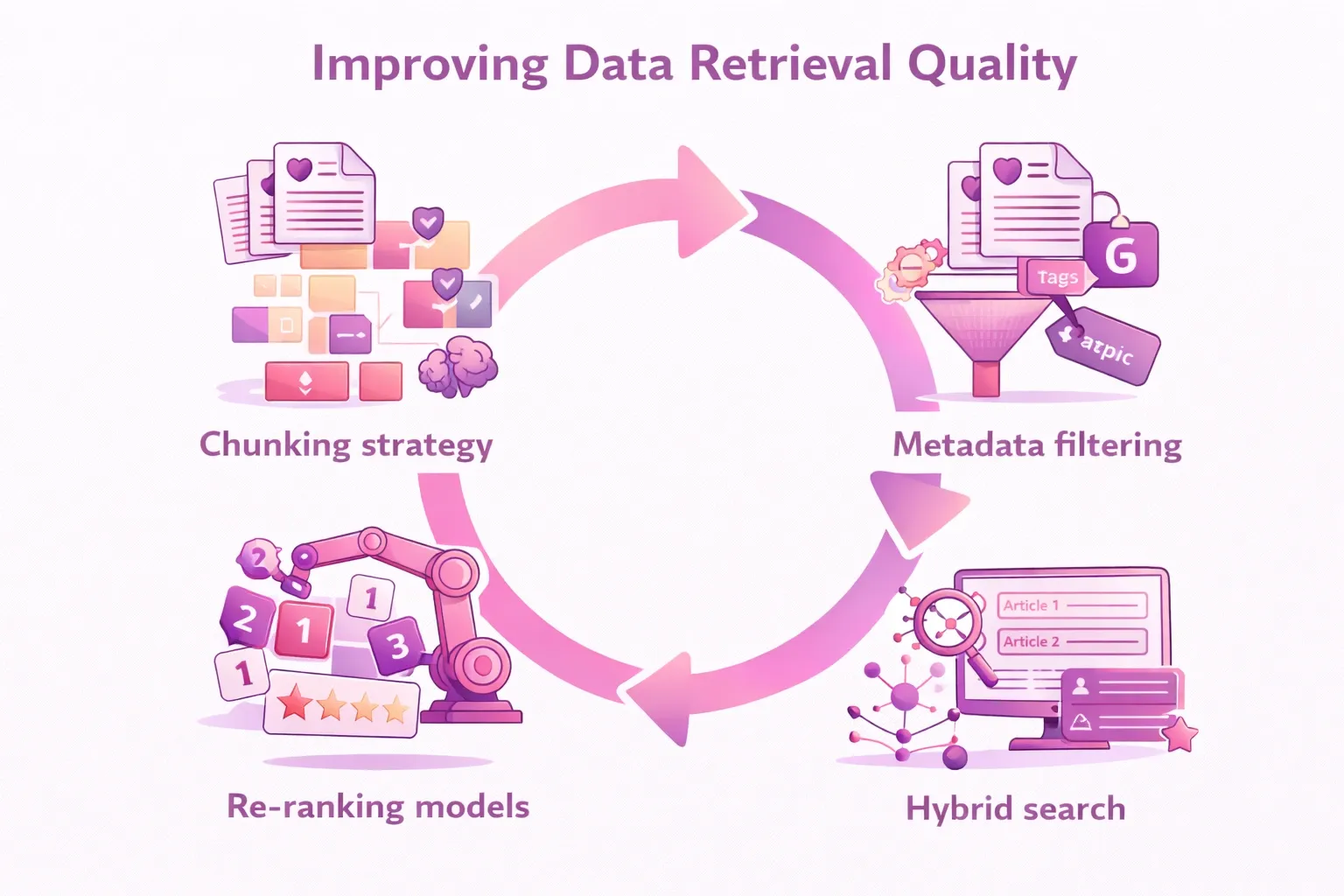
These are not theoretical optimizations. They are the difference between a RAG system that production teams trust and one they quietly abandon. For a deeper dive into advanced RAG optimization strategies, Intertec’s Escape the Naiveness of RAG covers best practices for chunking, retrieval tuning, and vector store management in production.
Choosing the Right Vector Database
Which Vector Database Is Best?
The honest answer? It depends. There is no universally "best" vector database - only the best one for your specific workload. Here are the key evaluation criteria we recommend for CTOs making this decision:
- Indexing performance - How fast can the system ingest and index new vectors? This matters for systems with continuous data ingestion.
- Query latency - What is the p95 latency for similarity search at your expected query volume?
- Horizontal scalability - Can the system distribute across multiple nodes as your dataset grows into billions of vectors?
- Filtering capabilities - Does the system support efficient pre-filtering or post-filtering with metadata? Some systems handle this far better than others.
- Integration with your AI stack - Does it integrate natively with LangChain, LlamaIndex, your embedding provider, and your orchestration layer?
Production Considerations
Selecting a vector store is only the beginning. Production deployments introduce additional concerns that teams frequently underestimate:
- Monitoring and observability—Track retrieval latency, index freshness, and query success rates. Without this visibility, retrieval quality degrades silently.
- Data refresh and re-embedding strategy—When your source documents change, you need a clear strategy for updating embeddings. Stale vectors lead to outdated or wrong answers.
- Security and multi-tenancy—In enterprise environments, namespace isolation and access control are non-negotiable. Ensure your vector store supports tenant-level data segregation.
- Cost-performance trade-offs—At scale, storage and query costs accumulate quickly. Evaluate cost per million queries alongside raw performance benchmarks.
Common Pitfalls in Implementing Vector Stores
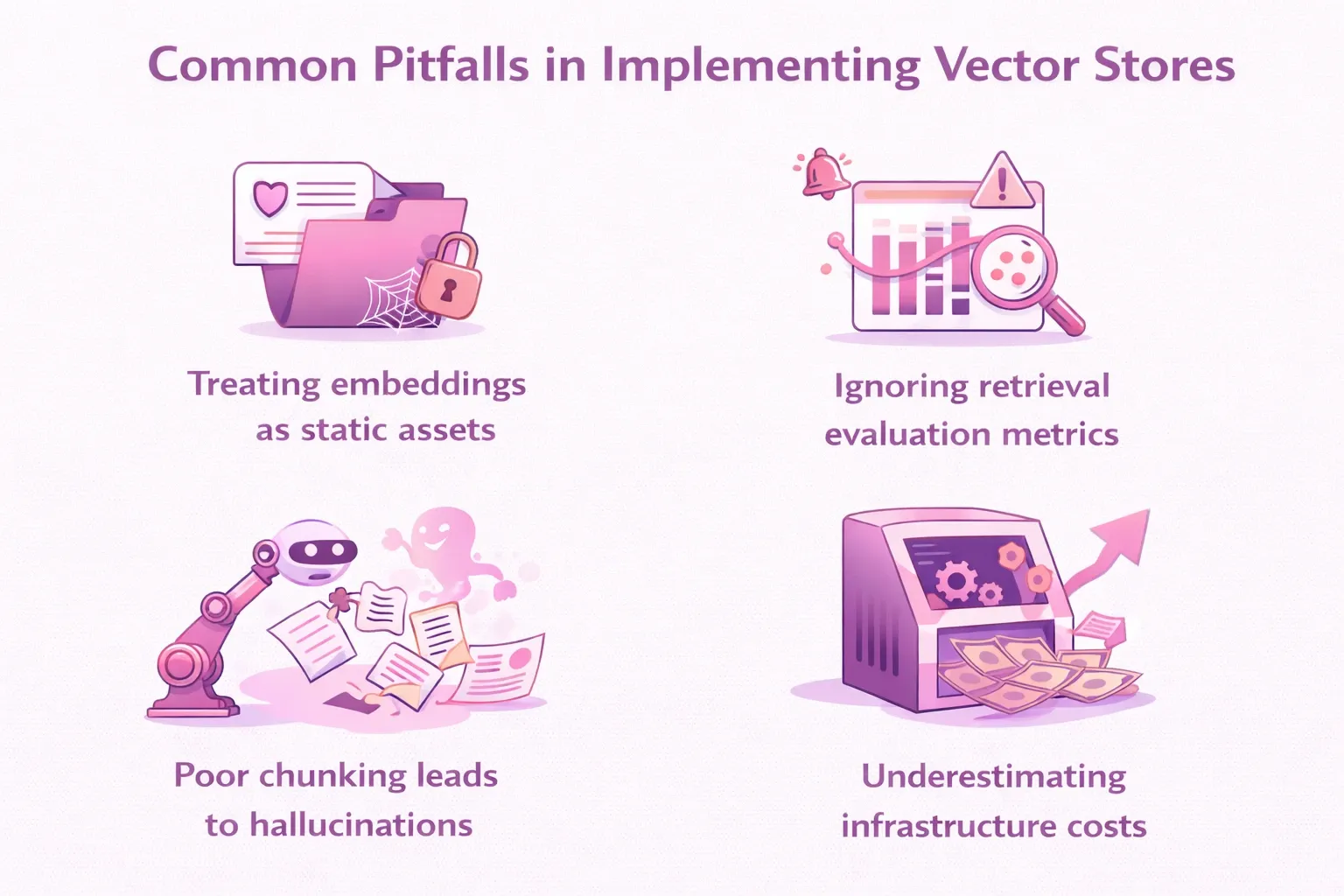
We have seen teams make the same mistakes repeatedly. Knowing these pitfalls in advance can save months of wasted effort.
Treating embeddings as static assets is a critical error. Embeddings are generated by a specific model at a specific point in time. When your embedding model updates - or when your source data changes—your vectors can become misaligned with queries, silently degrading retrieval quality.
Ignoring retrieval evaluation metrics is equally common. Teams spend enormous effort on LLM fine-tuning but deploy retrieval pipelines without any systematic evaluation. Tools like RAGAS provide reference-free metrics for measuring retrieval precision, recall, and faithfulness. Use them.
Poor chunking leads to hallucinations. If your chunks lose the surrounding context needed to answer a question, the LLM will fill the gap with plausible-sounding but fabricated information. Context-aware chunking is not a nice-to-have. It is a safety concern.
Underestimating infrastructure costs is a budget risk. Vector storage at scale is expensive, particularly for billion-vector datasets. Model this early, and factor in re-indexing costs, which can be substantial when embedding models are updated.
Conclusion: Vector Database as Core Parts of Modern AI Architectures
We have covered a lot of ground. Let us bring it together.
Vector stores are no longer experimental infrastructure—they are foundational to any serious AI application that needs to retrieve, contextualize, and ground responses in real data. They enable a form of data retrieval that traditional databases simply cannot match: semantic, probabilistic, and deeply aligned with how language models think.
When implemented thoughtfully, vector stores transform RAG pipelines from proof-of-concepts into production systems that actually deliver value. The enterprise momentum confirms this trajectory. RAG adoption jumped from 31% to 51% of enterprise AI implementations in a single year, according to Menlo Ventures. Vector database usage grew 377% year-over-year, per Databricks. These are not modest gains. These are signals of a category becoming core infrastructure.
As AI adoption accelerates, the question for CTOs is no longer whether to invest in vector stores. It is, which one, how to architect around it, and how to evaluate its performance over time. Get those decisions right, and your AI systems will be grounded, scalable, and trustworthy. Get them wrong, and no amount of LLM fine-tuning will save you.
The foundation matters. Make it solid.
Did this article help clarify how vector stores work and how to choose the right one for your AI stack? If so, please consider sharing it with colleagues and team members facing similar decisions. Let's raise the bar together.