Wenn Sie wissen, was Benutzer auf Ihren Websites in Echtzeit tun, erhalten Sie Einblicke, auf die Sie reagieren können, ohne auf die verzögerte Stapelverarbeitung von Clickstream-Daten warten zu müssen. In der AWS-Welt wird der gesamte Prozess durch AWS Kinesis vereinfacht. In diesem Artikel erfahren Sie, wie wir AWS Kinesis zum Erstellen von Echtzeit-Dashboards verwendet haben und wie wir einen vollständigen Überblick über die Vorgänge auf den Websites unserer Kunden zu Zeiten mit hohem Datenverkehr erhalten haben.
Die Herausforderung
Die Domains unseres Kunden, die über mehr als 20 Länder verteilt sind, bedienen Millionen von Benutzern. Der Kern der Domains ist der elektronische Handel, und so gibt es natürlich einzelne Zeiten im Jahr, in der Regel während der Feiertage oder großer jährlicher Rabatte, in denen der Verkehr auf den Domains seinen Höhepunkt erreicht, weil die Leute dann zu einem Einkaufsbummel neigen.
Für einen dieser Einkaufsbummel wollte der Kunde einen vollständigen Überblick über die Vorgänge auf seinen Websites in Echtzeit erhalten. Zur Veranschaulichung sind hier einige der Ereignisse aufgeführt, die nachverfolgt werden sollten:
- die Anzahl der aktiven Nutzer
- die Anzahl der Klicks
Architekturtools, die wir bereits verwenden
Es versteht sich von selbst, dass wir die Nutzer mit allen Ereignissen und Klicks zu jeder Zeit verfolgen. Der Unterschied besteht darin, dass uns die abschließenden Daten nicht in Echtzeit vorliegen, sondern wir sie stapelweise verarbeiten und sie frühestens mit einer Latenzzeit von 1 Stunde geliefert werden können. Eine solche Latenzzeit war für uns nicht akzeptabel, denn wir wollten überhaupt keine Latenzzeit - wir brauchten Echtzeit-Analysen für die eingehenden Ereignisse.
Was den Teil der Verfolgung und Verarbeitung angeht, verwenden wir bereits eine Palette von AWS-Services, darunter Lambdas, Kinesis Streams, EMR für die Datenverarbeitung, S3 für die Datenspeicherung, Redshift als analytische Datenbank usw.
Die Lösung muss sinnvollerweise in der umfangreichen AWS-Servicesammlung angesiedelt sein - eine Lösung, die auf allen bereits vorhandenen Tools aufbaut, ohne die vorhandenen Services zu beeinträchtigen und die Qualität der Ergebnisse zu gefährden.
Die Lösung und die wichtigsten Schritte
AWS bietet Echtzeit-Analysen mit Kinesis Data Analytics. Da wir bereits Kinesis Streams und Kinesis Firehose verwenden, um die aufgenommenen Daten an S3 zu liefern, waren wir von der Idee begeistert, den Service von der Stange zu nutzen, der mit den von uns bereits verwendeten Diensten kompatibel ist.
Wie funktioniert Kinesis Analytics?
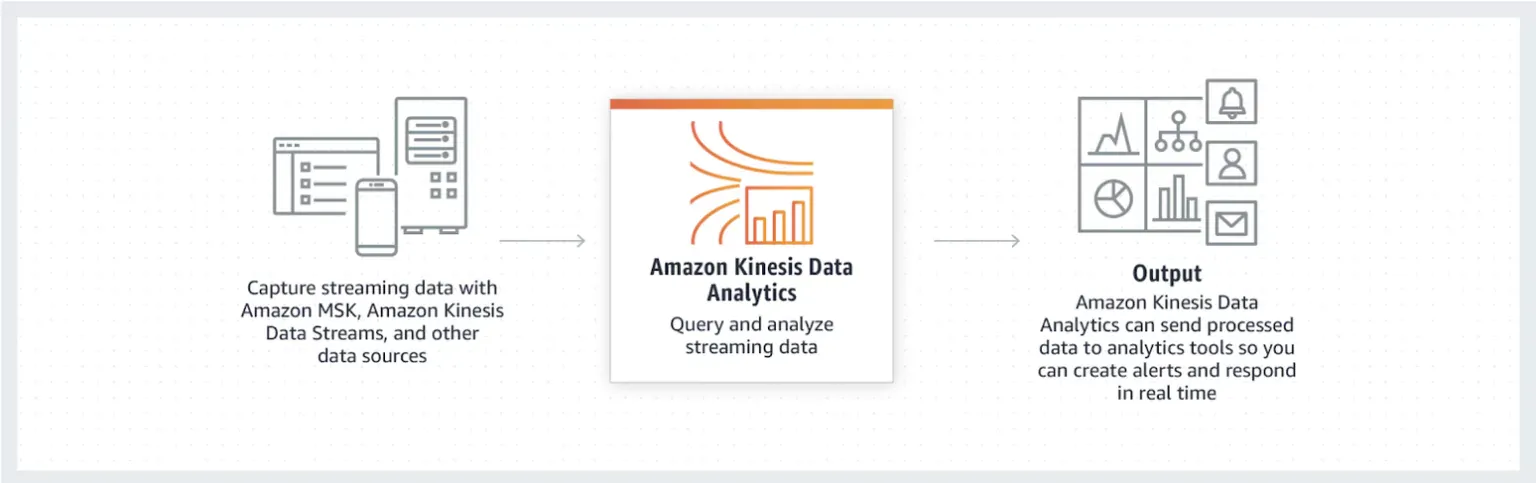
Eine Kinesis Analytics-Anwendung kann entweder mit einem Datenstrom oder einem Lieferstrom (auch bekannt als Firehose) verbunden werden, die beide Teil der AWS Kinesis-Toolbox sind. Das bedeutet, dass alle Daten, die diese Stream-Instanzen durchlaufen, von einer Kinesis-Anwendung eingesehen werden können. Mit einigen Modifikationen oder Besonderheiten können Sie wertvolle Informationen aus den Echtzeit-Ereignissen extrahieren und sie an einem sicheren Ort ausgeben, damit Sie sie lesen können.
Es gibt einige Arten von Datenfenstern, die sich als sehr nützlich erweisen. Die Daten können gefenstert werden durch:
- ein festes Zeit- oder Zeilenzählintervall (Sliding Window)
- zeitbasierte Fenster, die sich in regelmäßigen Abständen öffnen und schließen (Tumbling Window)
- ein verschlüsseltes zeitbasiertes Fenster, das mehrere sich überschneidende Fenster erlaubt, um verspätete oder ungeordnete Daten zu regulieren (Stagger Windows)
Hinweis: Die KA beeinflusst oder verzerrt nicht die ursprüngliche Ausgabe der Datenströme oder der Feuerschläuche. Sie zeigt lediglich die Neigung der Stalker zu Datenströmen.
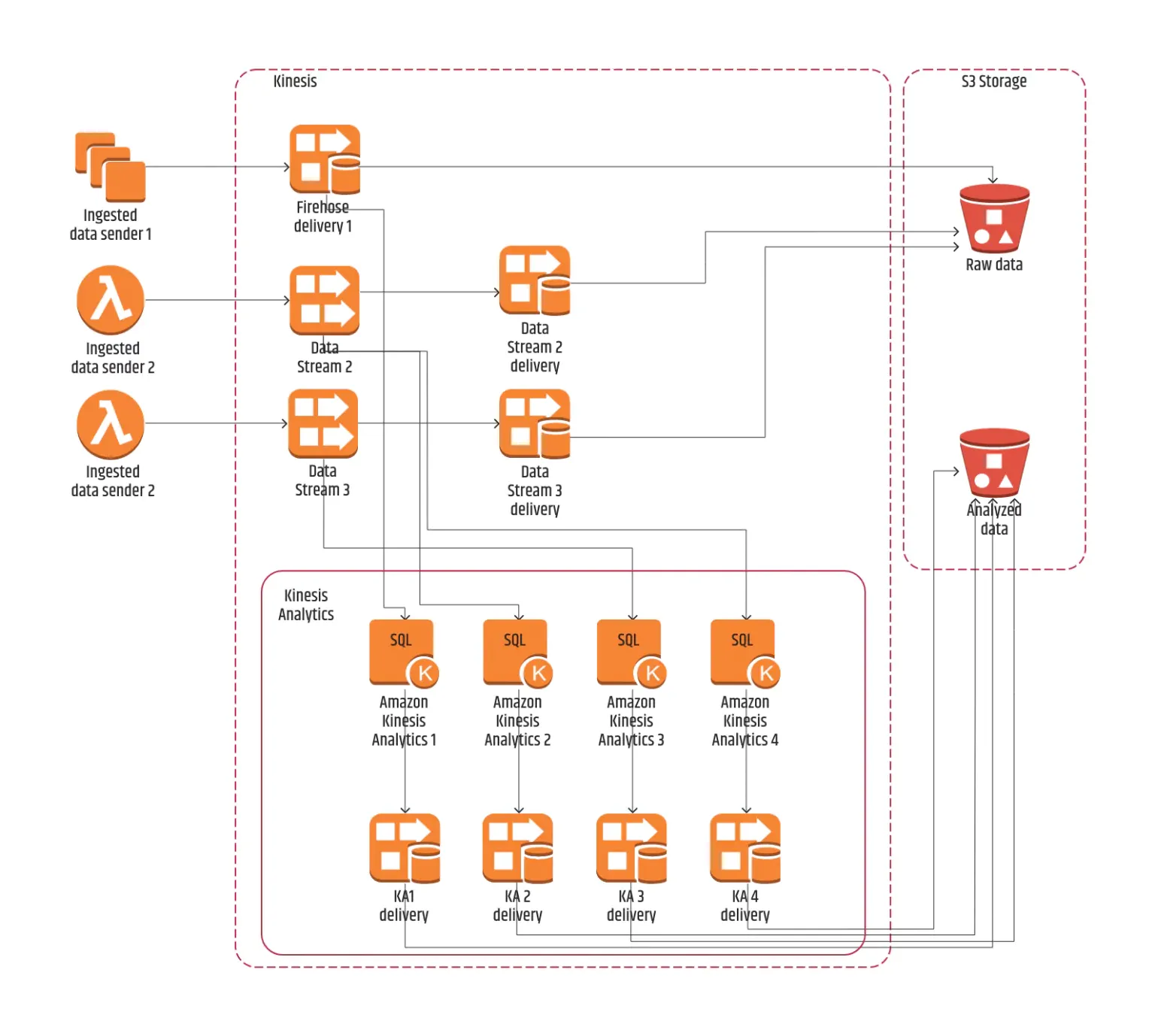
Schritt 1: Definieren der Datenquellen
Die benötigten Daten werden aus mehreren Quellen erzeugt. Zwei dieser Quellen senden die Daten an zwei verschiedene Kinesis Data Streams und eine einzelne Quelle sendet die Daten an einen Kinesis Firehose.
Mit anderen Worten, Kinesis Analytics sagt:
"Kein Problem, ich kann sowohl mit Kinesis Data Stream als auch mit Kinesis Firehose arbeiten."
Wir haben jedem unserer Streams eine spezifische KA-Anwendung zugeordnet, und nur ein Stream hatte zwei KA-Anwendungen, da wir denselben Stream für zwei separate Logikfraktionen benötigten.
Schritt 2: Auswahl der Laufzeit
Bei der Erstellung der Kinesis-Analytics-Anwendung gibt es zwei verschiedene Möglichkeiten, die Daten zu verarbeiten:
Wir entschieden uns für die Einfachheit und wählten SQL anstelle einer kompletten Flink-Anwendung. Anstatt ein Flink-Projekt einzurichten, die entsprechenden Konnektoren zu verwalten und es zu implementieren, haben wir einfach Abfragen direkt auf die eingehenden Daten geschrieben.
Mit SQL-Abfragen können Sie diese direkt in der Anwendung ändern und ausführen. Im Gegensatz zu einer Flink-Anwendung, bei der ein Jar erstellt und in die Kinesis Analytics-Anwendung implementiert werden muss, müssen Sie nicht jedes Mal die gesamte Anwendung neu bereitstellen, wenn Sie eine Änderung vornehmen. Während die Daten eingegeben werden, ist die Live-Ausgabe, die unter der Abfrage angezeigt wird, für den KA-Benutzer sehr vorteilhaft (wir haben jedoch noch einige Zweifel an der Genauigkeit dieser Ausgabe).
Schritt 3: Definieren des Schemas
Nachdem die Quelle der Kinesis Analytics-Anwendung festgelegt wurde, muss das Schema der eingehenden Datensätze definiert werden. Bonuspunkte gehen an Kinesis Analytics für seine Fähigkeit, verschachtelte _JSON_s zu lesen und die Felder aus diesen _JSON_s zu extrahieren.
Während wir die Vorteile des letzteren nutzen, mussten wir in dieser Phase einen Rückschlag hinnehmen, da einige spezifische Felder aus einem bestimmten Wert des gesamten JSON-Datensatzes stammen, der immer als stringifiziertes JSON innerhalb des Datensatzes gesendet wird. In diesem Fall ist die Kinesis Analytics-Anwendung nicht in der Lage, die Felder aus diesem String zu extrahieren.
Eine mögliche Lösung für dieses Problem ist die Verwendung einer Lambda-Funktion zur Vorverarbeitung der eingehenden Datensätze, bevor sie in KA verwendet werden (Lambda-Vorverarbeitung ist eine von KA selbst angebotene Funktion). Dieser Ansatz funktioniert gut, wenn wir den gesamten Prozess mit Mock-Daten simulieren. Sobald wir jedoch mit echten Produktionsdaten arbeiten, funktioniert alles für ein paar Minuten gut und bricht dann einfach ab, was beweist, dass dieser Ansatz unzuverlässig sein kann.
Schließlich mussten wir das Pre-Process-Lambda entfernen, also beschlossen wir, das stringifizierte JSON innerhalb des SQL-Skripts mit Regex zu parsen und die benötigten Informationen zu extrahieren. Das hat funktioniert.
Schritt 4: Ausgabe
Die Ergebnisse der Abfragen landen über Kinesis Firehose-Streams in einem S3-Bucket. Jede KA-Ausgabe hat ihren eigenen Ordner, und alle Firehoses der KA aus allen AWS-Regionen legen die Ergebnisse einfach an einem einzigen Ort ab.
Die Firehoses leiten die Daten als Parquet-Dateien zu einem niedrigen Speicherpreis weiter, die sich für eine optimale Abfrage mit Athena eignen. Zu diesem Zweck hatten wir Glue-Tabellen, die die Struktur der Ausgabedateien kennzeichneten.
Jede der Ausgabedateien hat eine eigene Tabelle, die nach Jahr, Monat, Tag und Stunde unterteilt ist.
Schritt 5: Templating der Infrastruktur
Alle im Analytics-Teil verwendeten Ressourcen werden mit CloudFormation-Vorlagen erstellt. Wir müssen mehrere AWS-Regionen abdecken (dieselben Ressourcen in allen Regionen), sodass die Vorlagen die Bereitstellung der Ressourcen in jeder Region erleichtern.
Dies bietet die Möglichkeit, alle Ressourcen durch Entfernen des CloudFormation-Stapels einfach zu löschen und sie zu einem späteren Zeitpunkt wiederzuverwenden, wenn wir diese Analysen erneut ausführen müssen.
Schritt 6: Nutzung
Diese Daten sollen (mit ein wenig Anreicherung aus anderen Redshift-Tabellen) die Echtzeit-Dashboards für Analysen in Tableau speisen.
Letztendlich werden die Daten von KA mithilfe von Redshift Spectrum aus S3 abgefragt, mit anderen Tabellen aus Redshift zur Anreicherung verbunden und zur Erstellung anschaulicher Dashboards verwendet.
Ergebnis und zukünftige Richtungen
Diese Erfahrung zeigt, dass Kinesis Analytics trotz eines fragwürdigen Verhältnisses zu KA während der Entwicklung tatsächlich sehr praktisch sein kann, um die gewünschten Ergebnisse zu erzielen.
Die Möglichkeit, eine Abfrage zu schreiben, auf "Ausführen" zu klicken und nach der Ausführung die Ergebnisse unter der Abfrage zu sehen, ist ein großes Plus für KA, auch wenn es viele Nachteile hat, wie z. B. die Tatsache, dass man auf die SQL-Validierung warten muss, dann darauf, dass die Anwendung läuft, die Quelldaten zum richtigen Zeitpunkt einspeisen muss und die Ergebnisse erst nach einigen Minuten erhält. Die Wartezeit ist selbst bei geringfügigen Änderungen lang, und wir fanden die "Geduldsprobe" seinerzeit nicht besonders reizvoll.
Ein weiterer Nachteil war, dass manchmal, wenn Sie das Quellschema ändern, nachdem Sie die gesamte KA-Anwendung erstellt haben, diese einfach beendet wird und nicht mehr funktioniert, ohne dass Sie einen Grund dafür erhalten.
Was wir jedoch als nützlich empfunden haben, ist die Tatsache, dass man mit KA und SQL - universellen und allgegenwärtigen Sprachen, die die meisten Leute in unserem Team (und in den meisten Datenteams) verstehen - Echtzeit-Streaming-Daten mit nur wenigen Klicks analysieren kann. Das ist in der Tat ein Vorteil, den man nutzen sollte, und er sollte bei der Entscheidungsfindung, ob man KA für Echtzeit-Analysen wählen sollte oder nicht, auf jeden Fall eine Rolle spielen.
Abschließende Worte
Wenn wir die Frage beantworten sollten, ob Kinesis Analytics für das, was wir erreichen wollten, ausreichend war, würden wir einfach antworten:
"Ja, es war ein ganz schöner Ritt, aber am Ende haben wir unser Ziel erfolgreich erreicht."
Wir würden auch hinzufügen, dass wir diese Lösung auf jeden Fall in Betracht ziehen würden, wenn wir in Zukunft etwas Ähnliches machen müssten, aber unsere Entscheidung würde auch sehr stark vom Anwendungsfall abhängen.