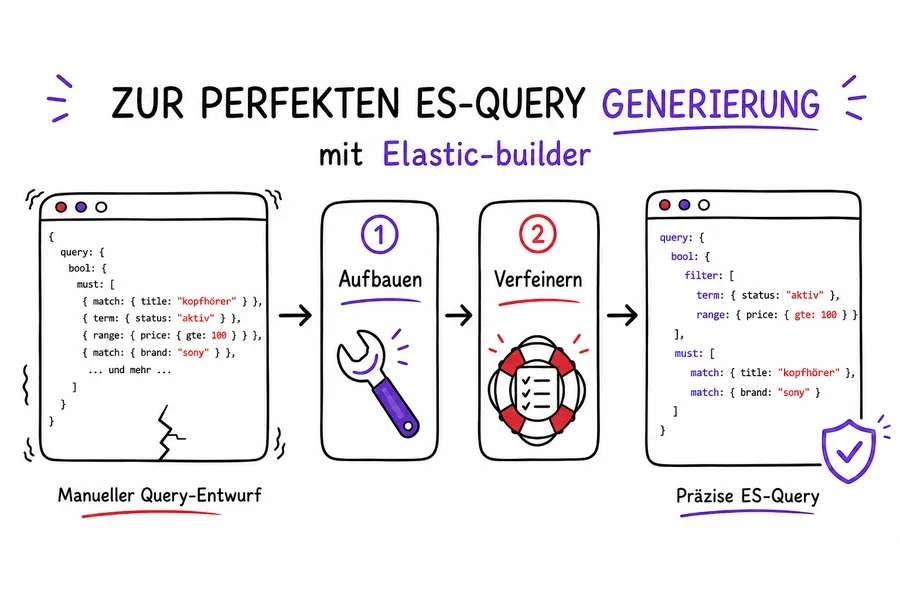
Bei allem Respekt vor dem, was ES(ElasticSearch) im Vergleich zu den anderen Speicher-Engines für die Abfrage von Daten bietet, ist einer seiner Nachteile die potenzielle Komplexität der Abfragen. Allgemein gesagt, wenn Sie ein Post-Objekt an einen ES-Endpunkt senden möchten, könnte die Konstruktion dieses Objekts komplizierter als gewöhnlich werden, insbesondere wenn das Ziel darin besteht, Daten durch Filterung abzurufen. Vor einigen Jahren gab es nicht viel Dokumentation darüber, wie man komplexe ES-Abfragen erstellt, und es gab auch nicht viele Werkzeuge wie Bibliotheken und Pakete für die Erstellung von ES-Abfragen. Dies änderte sich jedoch mit dem Aufkommen der elastic.js Lib für Javascript und insbesondere mit ihrem node.js Nachfolger - dem elastic-builder Paket.
Wie hat unsere Geschichte mit der ES-Abfragegenerierung begonnen?
Im Laufe von zwei Jahren haben wir an einem bestimmten Produkt gearbeitet, bei dem wir ES-Abfragen verwendet haben. Mit der Zeit wurde uns die Notwendigkeit bewusst, die Generierung solcher Abfragen zu optimieren. Jedes Mal, wenn wir etwas ändern mussten, war dies für uns mit einem hohen Aufwand verbunden. Also beschlossen wir, eine Lösung zu finden, um die Generierung von ES-Abfragen zu vereinfachen.
Nach vielen Überlegungen und Diskussionen haben wir schließlich das elastic-builder-Paket verwendet, um den Code für die Generierung von ES-Abfragen in unserem Angular-Projekt zu optimieren.
In diesem Beitrag werden wir nicht darüber sprechen, ob das Schreiben von benutzerdefiniertem Code eine bessere Lösung ist als die Verwendung eines Drittanbieter-Pakets oder ob Angular das am besten geeignete FE-Framework ist. Stattdessen werden wir uns nur auf einige Schlüsselsegmente unserer Lösung in Bezug auf die ES-Abfragen konzentrieren und sie in zwei Teilen erklären - Teil 1, der den ererbten Status zusammen mit den Hauptproblemen beschreibt, und Teil 2, der die verbesserte Lösung mit dem elastic-builder enthält.
Die Geburt unserer Abfrage
In der ersten Phase war die Anforderung eine einfache Filterung der Aufgaben nach verschiedenen Parametern wie Land, Status, etc. Zu diesem Zeitpunkt gingen wir davon aus, dass sich die Form der Abfrage nicht ändern würde, also schrieben wir mehrere Zeilen, um das Post-Objekt, das für die Bereitstellung der benötigten Ausgabe erforderlich ist, manuell einzustellen. Der unten gezeigte JSON-Baum war mehr oder weniger einfach:
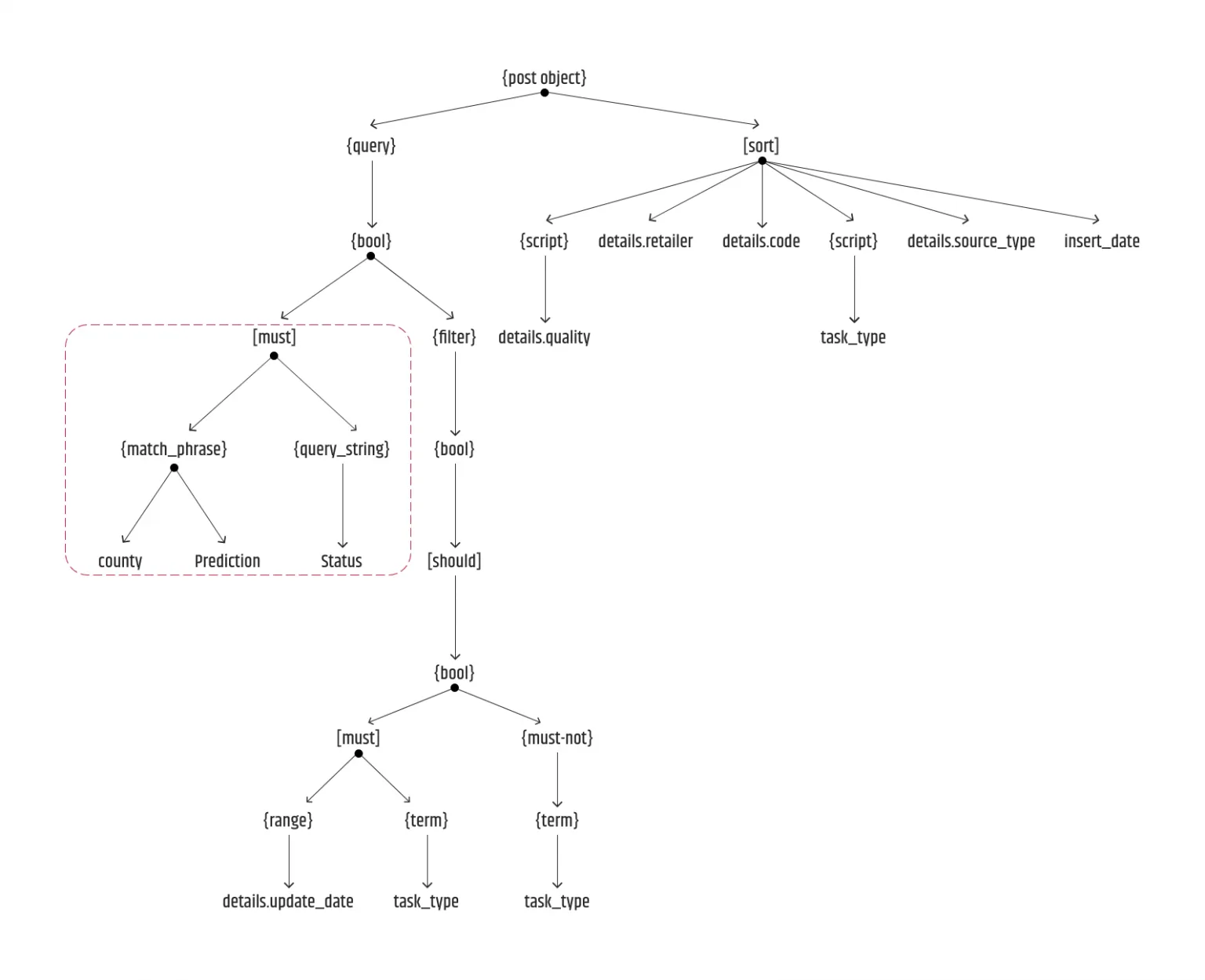
Um nur den Must-Teilbaum zu erzeugen, mussten wir mehrere Arrays, Objekte und Bedingungen verwenden, wobei zu berücksichtigen war, dass einige der Filter möglicherweise gar nicht existieren*(Vorhersage*) oder mehrere Werte haben können*(Status*):
let must: Array<any> = [ { "match": { "country": { "query": country, "type": "phrase" } } } ]; if (!!statusList.length) { let query = statusList.map(status => "(" + status + ")").join(' OR '); must.push({ "query_string": { "default_field": "status", "query": query }
}); } if (prediction) { must.push({ "match": { "prediction": { "query": prediction, "type": "phrase" } } }); } let boolObject = {"must": must}; let postObject = { "query": { "bool": boolObject } };
Die Ausgabe dieser Generierung entspricht dem, was wir wollten, da wir die Struktur der Abfrage im Voraus kennen mussten:
"query": { "bool": { "must": [ { "match": { "country": { "query": country, "type": "phrase" } } }, { "query_string": { "default_field": "status", "query": "(" + status_1 + ") OR (" + status_2 + ")" } }, { "match": { "prediction": { "query": Vorhersage, "type": "phrase" } } } ] } }
Wir haben einen ähnlichen Ansatz für die Teilbäume "Filter" und " Sort" verwendet, da wir der Meinung waren, dass der benutzerdefinierte Code für die Generierung der gesamten Abfrage wahrscheinlich groß genug war, um zu diesem Zeitpunkt eine Alternative in Betracht zu ziehen. Vorerst blieben wir beim Status quo und ahnten nicht, dass mehr und mehr Anforderungen früher als erwartet kommen würden.
Die Agonie der Erweiterung einer Abfrage
Im Laufe der Zeit wurde gefordert, dass die Abfragen benutzerdefinierte Suche, erweiterte Filterung, bedingte Filterung und so weiter bieten sollten. Darüber hinaus nahm die Anzahl der Filterwerte und Bedingungen drastisch zu. Jedes Mal, wenn wir versuchten, die Abfrage zu erweitern, war mehr und mehr benutzerdefinierter Code involviert, und wir waren uns nicht bewusst, dass dies den Generierungsprozess langsam verschmutzen würde. Dies führte zu mehr Fehlern als ursprünglich erwartet, und es wurde für die Entwickler, die erst kürzlich zu dem Projekt gestoßen waren, fast unmöglich, den Code zu verstehen.
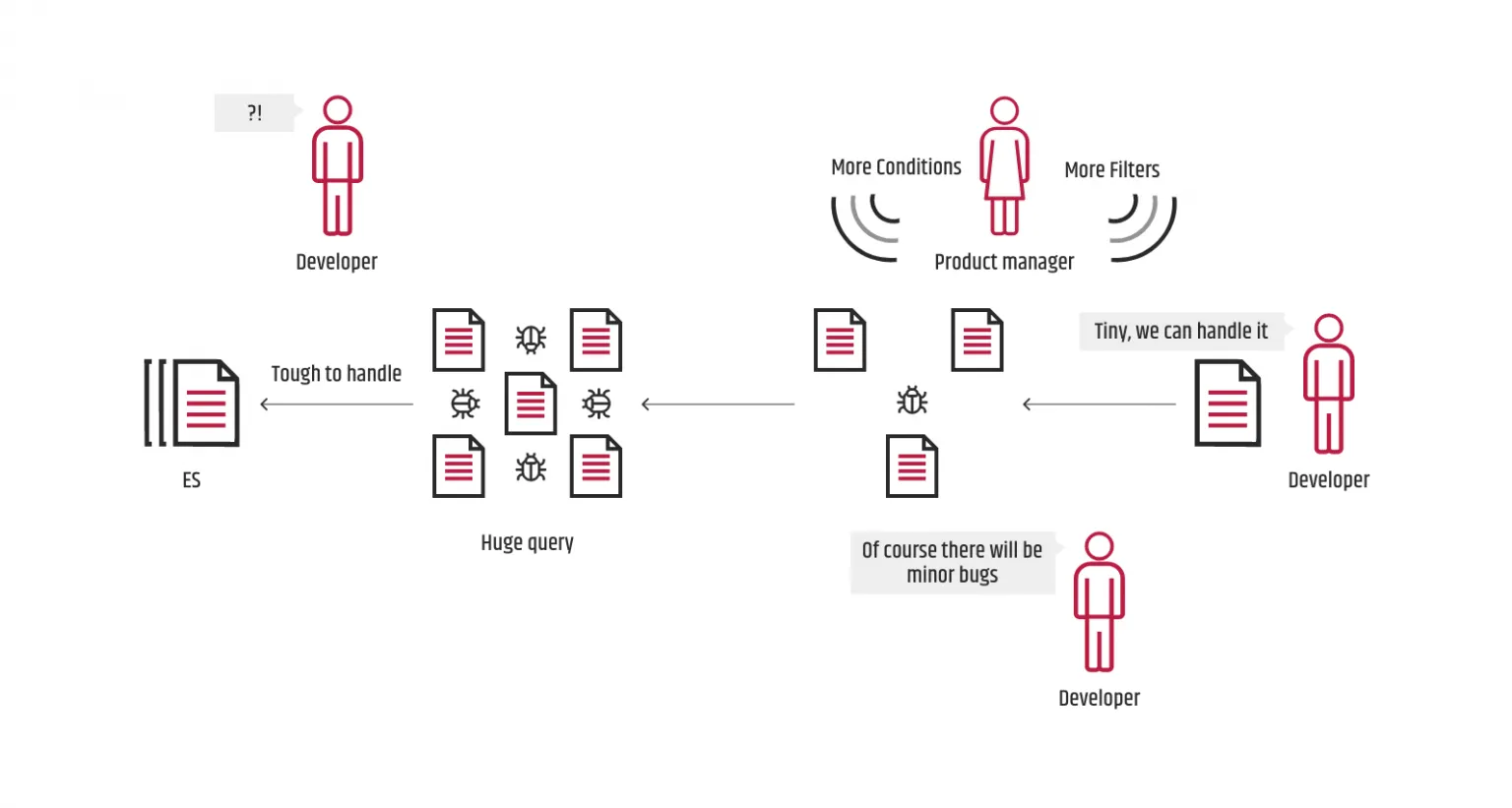
Bei solch komplexen Abfragen macht es keinen Sinn, zu zeigen, wie der JSON-Baum aussehen wird. Er wird einem Wald ähneln, da die verschiedenen Bedingungen für die Generationen in erster Linie auf den Statuswerten basieren, was immer zu einem separaten Baum pro Bedingung führt.
Das Gleiche gilt für den Code in der Generierungsmethode. Es ist unvorstellbar, einen solchen Code zu präsentieren, und deshalb werden wir uns im zweiten Teil des Blogbeitrags nur auf die kleineren Teile konzentrieren, die tatsächlich die wichtigsten Punkte darstellen, damit Sie in Betracht ziehen, dem elastic-builder eine Chance zu geben.