Ich nutze die Freiheit des Schreibens, die ein Blogbeitrag bieten kann, um potenzielle Leser zu warnen, dass der folgende Inhalt ausschließlich meine persönliche Meinung zu diesem Thema wiedergibt. Sie werden meinen Schreibansatz vielleicht ungewöhnlich finden, denn dieser Artikel über Softwaretechnologie ist kein typischer Artikel und wird keine Codeschnipsel, Zahlen oder prägnante Absätze enthalten.
Stattdessen werde ich meine persönlichen Erfahrungen und Ansichten zu mehreren Projekten darlegen, die einige Aspekte der Künstlichen Intelligenz integriert haben. Mit KI beziehe ich mich auf das größtmögliche Feld, das maschinelles Lernen, Datenwissenschaft, Robotik und so weiter umfasst, auch wenn die Tendenz heutzutage dahin geht, stattdessen einige dieser Teilbereiche zu verwenden.
In den letzten zwei Jahrzehnten habe ich an mehreren Projekten und Forschungsaktivitäten mitgewirkt, die sich mit verschiedenen Aspekten der KI befassten, angefangen bei der grundlegenden Verarbeitung von Zeichenketten, bei der die meisten Algorithmen von Grund auf neu entwickelt werden mussten, bis hin zur Sprach- und Spracherzeugung unter Verwendung einer Vielzahl von Software mit bereits eingebauten Algorithmen. Aufgrund dieser häufigen Veränderungen in der Welt der KI befand ich mich zumeist in schwierigen Situationen.
Einige wurden durch die Schwierigkeiten verursacht, Standardarbeitsmethoden zu erkennen und anzuwenden. Andere waren das Ergebnis der "trockenen" Perioden, in denen mein Geist mit anderen Projekten beschäftigt war, was dazu führte, dass ich Schwierigkeiten hatte, die "Wissenslücken" zu füllen. Die harte Erfahrung in Verbindung mit vielen Stunden "unnötiger" Entwicklungsarbeit ließ mich jedoch die Bedeutung der Etablierung von KI-Standards und der technischen Revolution im Cloud Computing schätzen.
Aus diesem Grund werde ich im folgenden Artikel versuchen, all diese vergangenen Momente mit den aktuellen Herausforderungen zu verknüpfen, die man als Einzelperson, als Team oder als Institution bei der Arbeit an einem KI-Projekt erleben kann.
Lassen Sie uns beginnen. Die Frage ist: Wie?
KI ist schon seit mehreren Jahrzehnten ein Hype. Diejenigen, die sich mit der Entwicklung solcher Lösungen befassen, denen aber gleichzeitig die Erfahrung fehlt, sind sich der Schwierigkeiten, auf die sie auf ihrem Weg stoßen könnten, nicht wirklich bewusst. Außerdem haben sie oft keinen Plan, wie sie anfangen sollen, obwohl es mehrere Möglichkeiten gibt, von denen einige in Betracht gezogen werden können:
- sich nur auf die geschäftlichen Anforderungen zu konzentrieren und ein anderes Fachgebiet mit der Lösung zu betrauen
- sich an ein anderes, erfahreneres Fachgebiet wenden und dessen Beratungsdienste für die interne Entwicklung in Anspruch nehmen;
- sein eigenes Wissen zu erweitern und Forschungsarbeiten durchzuführen, die für jedes anstehende Projekt von Nutzen sind.
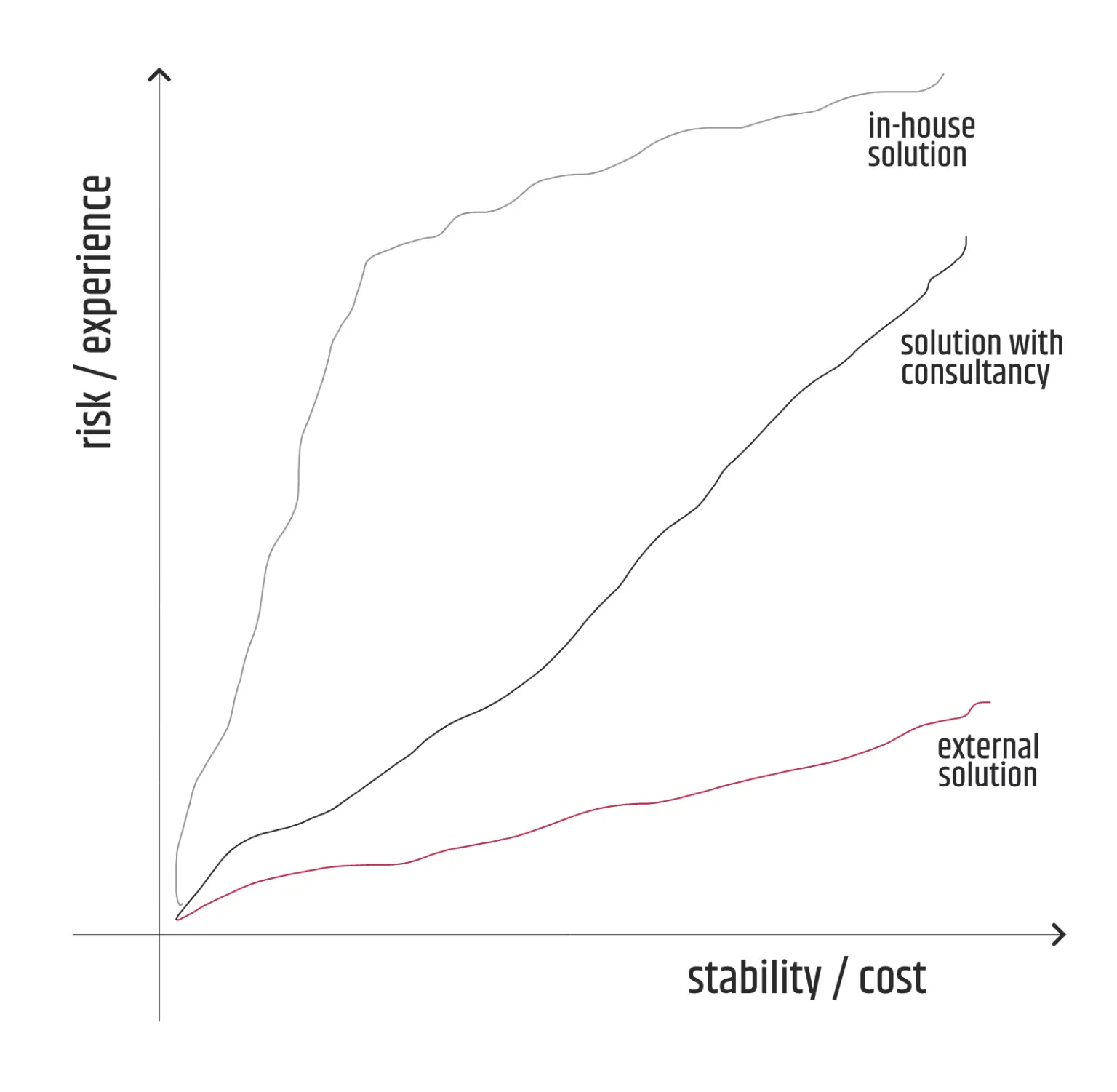
Es ist verständlich, dass die erste Option oft teurer ist, aber sie minimiert gleichzeitig das Risiko, dass die Lösung nicht oder nur unzureichend umgesetzt wird. Stellt sich die Lösung jedoch als völlig erfolglos heraus, geht der Initiator des Themas fast völlig leer aus, abgesehen von der schlechten Erfahrung, die er gemacht hat.
Andererseits kann die dritte Option ein großes Risiko darstellen, aber selbst wenn das Ergebnis des Projekts zum Scheitern verurteilt ist, bleibt der Nutzen der Investition, insbesondere in Form von Wissen und Erfahrung, definitiv erhalten und kann für die nächsten ähnlichen Projekte genutzt werden. Als langfristiger Ansatz ist sie daher weitaus vielversprechender als die erste und ich empfehle, sie generell zusammen mit der zweiten Option zu verfolgen, sofern sie nicht zu sehr von den Beratungsdiensten beeinflusst wird.
Sammeln von Ressourcen
Wenn ich von Ressourcen spreche, meine ich vor allem Menschen und Technologie. Selbst mit den neuesten Software-Fortschritten ist es schwierig, ein KI-Projekt allein zu bearbeiten. Sie müssen zumindest ein kleines Team von Personen zusammenstellen, die über die erforderliche Mindestkapazität verfügen und motiviert sind, hart zu arbeiten. Letzteres gilt vor allem deshalb, weil die Entwicklung einer KI-Lösung schwierig, langwierig und ungewöhnlich sein kann - etwas, woran ein gewöhnlicher Ingenieur normalerweise nicht gewöhnt ist.
Um eine "intelligente" Lösung auf den Markt zu bringen oder die Genauigkeit zu erhöhen, sind die entsprechenden Aufgaben oft sehr repetitiv. So kann es zu einem "Effekt" der Demotivation oder der mangelnden Bereitschaft kommen, das Niveau des Beitrags zu erhöhen, der jedes Teammitglied jederzeit treffen kann.
Was die verwendeten Technologien angeht, so hat sich die Situation im Vergleich zu der vor zwei Jahrzehnten verfügbaren Software-Qualität und -Quantität drastisch verbessert. Es gibt "tonnenweise" äußerst nützliche Sprachen, Plattformen, Frameworks, Bibliotheken, Tools und obendrein Cloud-Dienste mit ausführlicher Dokumentation, Lernmaterial/Kursen und Beispielen. Das bedeutet, dass heute selbst ein fortgeschrittener Ingenieur eine bessere Möglichkeit hat, die Verwendung der Software in der Praxis zu erlernen.
Danach stellt sich natürlich die Frage: Brauchen wir ein Team, das aus Personen besteht, die spezielle Aufgaben für das Projekt erfüllen? Oder um die Frage anders zu formulieren: Warum nicht Generalisten statt Spezialisten?
Natürlich ist es schön, einen zertifizierten ML-Ingenieur oder einen Datenanalysten mit mehrjähriger Erfahrung zu haben, aber das ist keine zwingend zu erfüllende Bedingung. Und in der Realität ist es schwer, sie zu erfüllen, weil der Verfügbarkeits-Pool nicht so groß ist.
Wenn es beispielsweise um die Entwicklung geht, reicht es aus, Ingenieure mit der richtigen Einstellung und Erfahrung in mindestens einer der führenden KI-Sprachen zu finden, was in erster Linie auf Python oder Java und Javascript zutrifft, die nicht weit dahinter liegen, und die sich an die Arbeitsprinzipien anpassen können, die sich von der Standard-Projektentwicklung unterscheiden.
Wie sieht es mit den Arbeitsprinzipien aus?
Generell gibt es einen Unterschied in der Herangehensweise, wenn man sich mit einem KI-Projekt beschäftigt. Es ist definitiv eine einzigartige Möglichkeit, aber mehr oder weniger liefert die KI-Lösung eine "Intelligenz", die etwas "Intelligentes" tut, entweder als "Spiegel" des menschlichen Verhaltens oder etwas, das eine natürliche Intelligenz niemals selbst tun kann.
Bevor wir uns mit den Einzelheiten des KI-Projekts befassen, muss ich eine wichtige Sache erwähnen, der nicht viele Aufmerksamkeit schenken - die Terminologie. In diesem Artikel werde ich den Leser so weit wie möglich von hochtrabenden Worten und Beschreibungen verschonen. Das bedeutet jedoch nicht, dass ich Angst habe, missverstanden zu werden, sondern ich sage es einfach, weil es keine genauen Standards oder eine klar definierte Namenskonvention gibt. Mit anderen Worten: Der KI-Welt fehlt etwas, was beispielsweise das WWW in Form des W3C besitzt.
Im Laufe der Jahre habe ich auch miterlebt, wie sich die KI-Terminologie verändert hat. Sie hat sich nicht nur aufgrund der neuen Errungenschaften weiterentwickelt, sondern sie wurde "refaktorisiert", was sich auf die Teile bezieht, die ihren Zweck nicht geändert haben. Ursprünglich waren es die wissenschaftlichen Einrichtungen (vor allem Universitäten), die die Entwicklung vorantrieben, doch in den letzten 15 Jahren übernahmen die führenden Cloud-Anbieter die Führung, so dass der Kampf um die Standards zu einer nicht enden wollenden Geschichte wurde, auch wenn Forscher wie Geoffrey Hinton oder Jeff Hawkins versuchen, in ihrer Arbeit Kompromisse zu schließen.
Einige von Ihnen werden sich vielleicht daran erinnern, dass bei der Angabe von Eingabevariablen das Wort Spalte mehr genutzt wurde als das Wort Merkmal. Ein anderes Beispiel ist die Frage, ob es sich um ein Label oder eine Ausgabeklasse handelt. Oder warum verwendet man das Wort Hyperparameter anstelle eines Arguments? Ähnlich verhält es sich mit den Begriffen Prädiktion, Inferenz und Generierung, die oft missbräuchlich verwendet werden.
Sie fragen sich vielleicht, warum ich so viel Wert auf die Terminologie lege?
Nun, das ist ganz einfach. Wenn das Projekt anläuft, werden Verfahren wie Besprechungen, Dokumentation und jede Art von Kommunikation plötzlich zu einem Muss. Die Wahrscheinlichkeit, dass es zu Missverständnissen zwischen den Teammitgliedern kommt, ist groß. Daher ist der erste Ratschlag, den ich jedem Team bei der Festlegung der Arbeitsgrundsätze geben möchte, sich auf die Terminologie zu einigen, auch wenn sie nicht den (wahrscheinlich nicht existierenden) Standards entspricht, angefangen bei den einfachsten (consts, vars) bis hin zu den komplexeren - den Phasen der Arbeitspipeline.
Die Arbeits-Pipeline sollte ebenfalls einbezogen werden, da sie anfällig für Änderungen und Varianten ist, auch wenn derzeit eine der populärsten Methoden als Grundlage für die meisten Pipelines da draußen dient. Dazu gehören auch die, die von Anbietern von KI-Cloud-Diensten wie AWS empfohlen werden. Andererseits ist jedes Projekt einzigartig und kann nicht immer durch diese Phasen abgedeckt werden, oder in einigen Fällen werden sogar die Standardphasen überhaupt nicht berücksichtigt.
Daher empfehle ich, zunächst mit der CRISP-DM-Methodik zu beginnen und die Phasen oder die Prozesse innerhalb jeder Phase nur minimal zu verschieben, einzuführen oder zu entfernen. Aus meiner Sicht können die "großen Drei" niemals weggelassen werden:
- Problemformulierung
- Datenaufbereitung
- Modellierung
Bei allem Respekt für die Phasen des Datenverständnisses, der Evaluierung und der Bereitstellung sind einige ihrer Prozesse hinsichtlich ihrer Position in der Pipeline flexibel.
Beispielsweise ist das Datenverständnis in der Regel eng an die Datenermittlung in der Problemframing-Phase gekoppelt. Und die Bewertung kann an die Modellierungs- oder die Implementierungsphase gebunden sein. Das Problemframing hingegen ist oft als Geschäftsverständnis zu finden, auch wenn es nur ein Prozess (der erste) als Teil dieser Phase ist. Schließlich kann die Einführungsphase übersprungen werden, insbesondere bei Forschungsprojekten oder Proof of Concepts. Stattdessen können Sie eine allgemeinere Nutzungsphase verwenden.
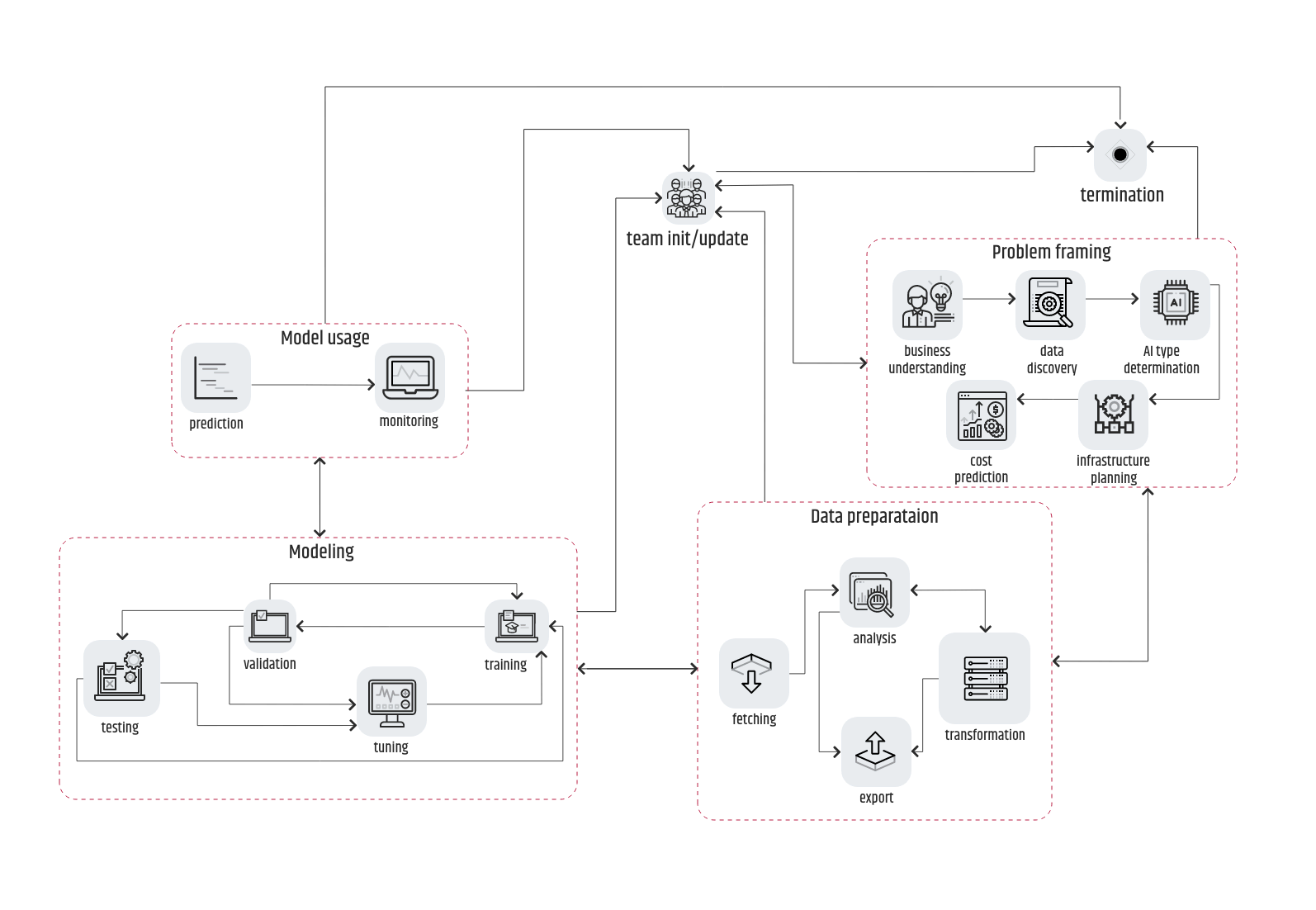
In der obigen Abbildung ist zu erkennen, dass die Pfeile, die die einzelnen Phasen, die eine Variante der CRISP-DM-Pipeline beschreiben, miteinander verbinden, bidirektional sind.
Das bedeutet, dass die Abfolge Problemstellung -> Datenaufbereitung -> Modellierung -> Nutzung immer auch in umgekehrter Richtung möglich ist. Zum besseren Verständnis stellen Sie sich vor, dass es während des Validierungsprozesses Ausrutscher gibt, die auf einen unzureichenden Trainingsdatensatz hindeuten. Das bedeutet, dass die Datenaufbereitung nicht wie erwartet "funktioniert" hat und wiederholt werden muss. Im Falle eines "_Houston, wir haben ein Problem_"-Ereignisses müssen alle Teammitglieder auf den neuesten Stand gebracht werden und entweder den Ablauf der Pipeline von Anfang an wiederholen oder im schlimmsten Fall das gesamte Projekt beenden.
Wie ich bereits in der Einleitung erwähnt habe, gab es eine Zeit, in der die meisten KI-Algorithmen von Grund auf neu geschrieben werden mussten, weil es keinen externen Anbieter gab, der den Entwickler unterstützen konnte. Und da das Ergebnis des Projekts von der Qualität des Algorithmus abhing, lag der Schwerpunkt auf der erfolgreichen Bestimmung des KI-Typs des Geschäftsproblems. Wenn etwas schief ging, dauerte die Wiederherstellung viel länger, weil die Entwicklung des Ersatzalgorithmus von vorne beginnen musste.
Heutzutage, mit der Verfügbarkeit von Bibliotheken und Diensten, die hochleistungsfähige Algorithmen bereitstellen, die fast alles abdecken, von komplexen Graphen-Traversal-Algorithmen bis hin zu Word2Vec-Konvertierungen, hat der KI-Typ-Bestimmungsprozess den "Thron" an die Datenaufbereitungsprozesse verloren. Selbst wenn der KI-Typ "falsch" ist und ein ungeeigneter Algorithmus verwendet wird, kann dieser in der Regel leicht ersetzt werden, ohne dass der Trainingsdatensatz (m)eine Änderung erfährt, was bedeutet, dass die nachfolgenden Prozesse oft gleich bleiben.
Wenn die Arbeit erst einmal begonnen hat, wird es einige Zeit dauern, bis sich ein Ingenieur an den Arbeitsablauf gewöhnt hat. Aber nach mehreren Iterationen wird das Team flüssiger und findet die Pipeline sehr nützlich für die Fortschrittsverfolgung. Ein Hindernis kann darin bestehen, einen Weg zu finden, sie in die bereits eingeführte Entwicklungsmethodik zu integrieren.
Kann sie agil sein?
Bevor ich auf weitere Details eingehe, wollen wir einen Blick auf die möglichen Wege werfen, die Arbeitspipeline in die gewohnte Methodik zu integrieren, die ein Team oder eine Organisation nicht aufgeben will. Nicht bereit zu sein, die bewährte Methodik aufzugeben, ist überhaupt keine schlechte Sache, vor allem, wenn sie zuvor erfolgreich war. Aber das Bestreben, eine Pipeline zu integrieren, die wahrscheinlich nicht "passt", kann eine ziemliche Herausforderung sein.
In letzter Zeit findet man im Internet eine Vielzahl von Inhalten über das Konzept der Agilen Datenwissenschaft. Die meisten der geschriebenen Artikel sind das Ergebnis tiefgreifender Analysen, aber manchmal mit widersprüchlichen Zusammenfassungen. Ich möchte jedoch niemanden mit den Schlussfolgerungen in diesen Zusammenfassungen belästigen. Stattdessen werde ich versuchen, einige Punkte anzusprechen, die es meiner Meinung nach wert sind, eine Chance zu bekommen.
Wenn man davon ausgeht, dass ein KI-Projekt mit einer definierten Pipeline in den agilen Entwicklungsalltag eines Teams integriert werden soll, dann hat man zunächst den Eindruck, dass dies eher mit Kanban als mit Scrum möglich ist.
In Wirklichkeit hängt die Wahl wiederum von der Flexibilität der Ressourcen - Team + Zeit - ab. Nehmen wir an, wir haben eine agile Arbeitsmethodik, d.h. eine Reihe von gut definierten Aufgaben, und die Details sind wie folgt:
1. Zunächst berücksichtigen wir die Risikofaktoren und beginnen dann mit der Aufgabenplanung. Bei einem Forschungsprojekt oder einem Proof of Concept kann diese Aufgabenplanung jedoch außer Acht gelassen werden. Um den Kunden zufrieden zu stellen, muss der Product Owner vorsichtig sein, wenn er eine Lieferung verspricht, da man nicht 100%ig sicher sein kann, in welcher Iteration der Pipeline sie stattfinden kann. Gleichzeitig darf der Aufwand für den Entwickler nicht drastisch erhöht werden. Die Festlegung von Meilensteinen kann helfen, aber gleichzeitig sollten sie nicht zu spezifisch sein. Ein schlechtes Beispiel wäre "Freigabe eines Modells mit 80 % Genauigkeit innerhalb eines Monats", ein gutes Beispiel wäre "Freigabe eines Funktionsmodells innerhalb eines Monats". Die Planung sollte einen Kompromiss zwischen der Sichtweise des Produktmanagers und der des Entwicklers darstellen. Natürlich kann dies nicht für F&E oder Proof of Concept gelten, wo die Festlegung von Fristen vermieden werden sollte, um den Forschungsfluss nicht zu stören. Es sei denn, die Arbeitsintensität ist nicht zufriedenstellend.
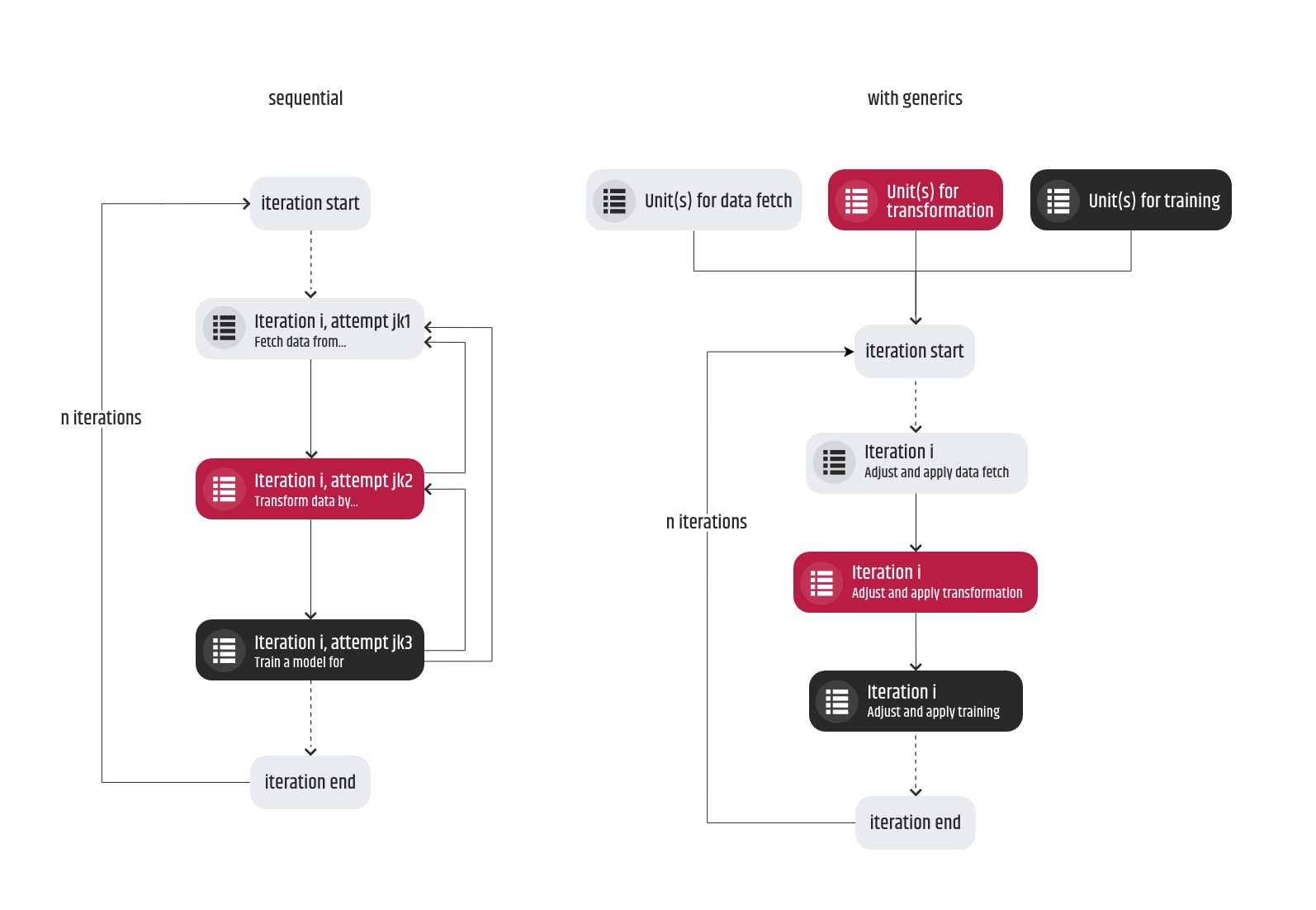
2. Es wird Situationen geben, in denen mehrere Aufgaben gleichzeitig in Angriff genommen werden können. Auch wenn Sie die Möglichkeit haben, Ihre Arbeit zu parallelisieren, was den Arbeitsablauf potenziell beschleunigen kann, müssen Sie die möglichen Umkehrungen im Auge behalten, wenn Sie eine Aufgabe zu früh beginnen und abschließen. Dieses Szenario tritt in der Regel auf, wenn sich die Anforderungen auf einen Prozess beziehen, der erst viel später in der Pipeline kommt, und die Prozesse davor noch nicht implementiert wurden. Wenn die Vorgängerprozesse fertig sind, können die alten Anforderungen obsolet werden, und wenn das passiert, muss die ursprüngliche Aufgabe wiederholt werden, diesmal aber mit aktualisierten Anforderungen. Es gibt zwei Möglichkeiten, den Rückschlag in diesem Szenario zu beheben. Erstens kann die Reihenfolge der Aufgaben, die der Pipeline entsprechen, beibehalten werden, so dass z. B. der Transformationsprozess (des Datensatzes) nicht vor dem Training freigegeben wird. Zweitens müssen die Code-Einheiten (Skripte, Module, Methoden, ...) so generisch wie möglich entwickelt und strukturiert werden, und es sollte jede Möglichkeit genutzt werden, sie konfigurierbar zu machen, so dass häufige Änderungen der Anforderungen derselben Aufgabe keine wesentlichen Änderungen in der Entwicklung verursachen.
3. Mehrere Iterationen der gleichen Aufgabe sind nicht ungewöhnlich und sollten kein Problem darstellen. Nehmen wir an, wir haben eine Aufgabe zum Trainieren eines Modells auf der Grundlage eines Datensatzes, der in einer der vorherigen Aufgaben vorbereitet wurde. Nach erfolgreichem Abschluss der Aufgabe ist das Ergebnis nicht zufriedenstellend. Infolgedessen werden die nächsten beiden Aufgaben in der Form "bereite einen Datensatz für das Training auf eine andere Art und Weise vor" und "trainiere ein Modell auf der Grundlage des letzten vorbereiteten Datensatzes" kommen - also eine ziemlich ähnliche und eine andere fast die gleiche, aber unter anderen Bedingungen.
4. Ich habe den Trainingsprozess absichtlich erwähnt, weil es ratsam ist, eine separate Aufgabe für ein einzelnes Training zu verwenden, anstatt es in andere Aufgaben einzubinden. Wenn man den Schwerpunkt der Ausbildung reduziert, können die Hauptanforderungen der Aufgabe zu einem Schätzungsproblem führen.
5. Bei der ersten Iteration der Pipeline sollte ein Protokollierungsmuster festgelegt und angewendet werden. Genauer gesagt, wenn ein Prozess mit irgendeiner Art von Output entwickelt wird, hilft das Führen von Protokollen über die gewünschten Metriken, den Fortschritt über mehrere Iterationen hinweg abzuschätzen. Die Einführung der Protokollierung erfolgt in der Regel in der Datenvorbereitungsphase, nachdem der Datenabrufprozess abgeschlossen ist. Sie ist wichtig für das Training, die Validierung, das Testen und die Prozesse in der Nutzungsphase. Die Protokollierung sollte pro Prozess durchgeführt werden. Mit der Zeit können die Protokolle erweitert werden, wenn bestimmte Erklärungslücken entdeckt werden. Die Analyse und Diskussion der Protokolle ist wesentlich für einen Überblick über die tatsächliche Leistung bei jeder Trainingsiteration und trägt somit zur Einschätzung des Projekterfolgs bei.
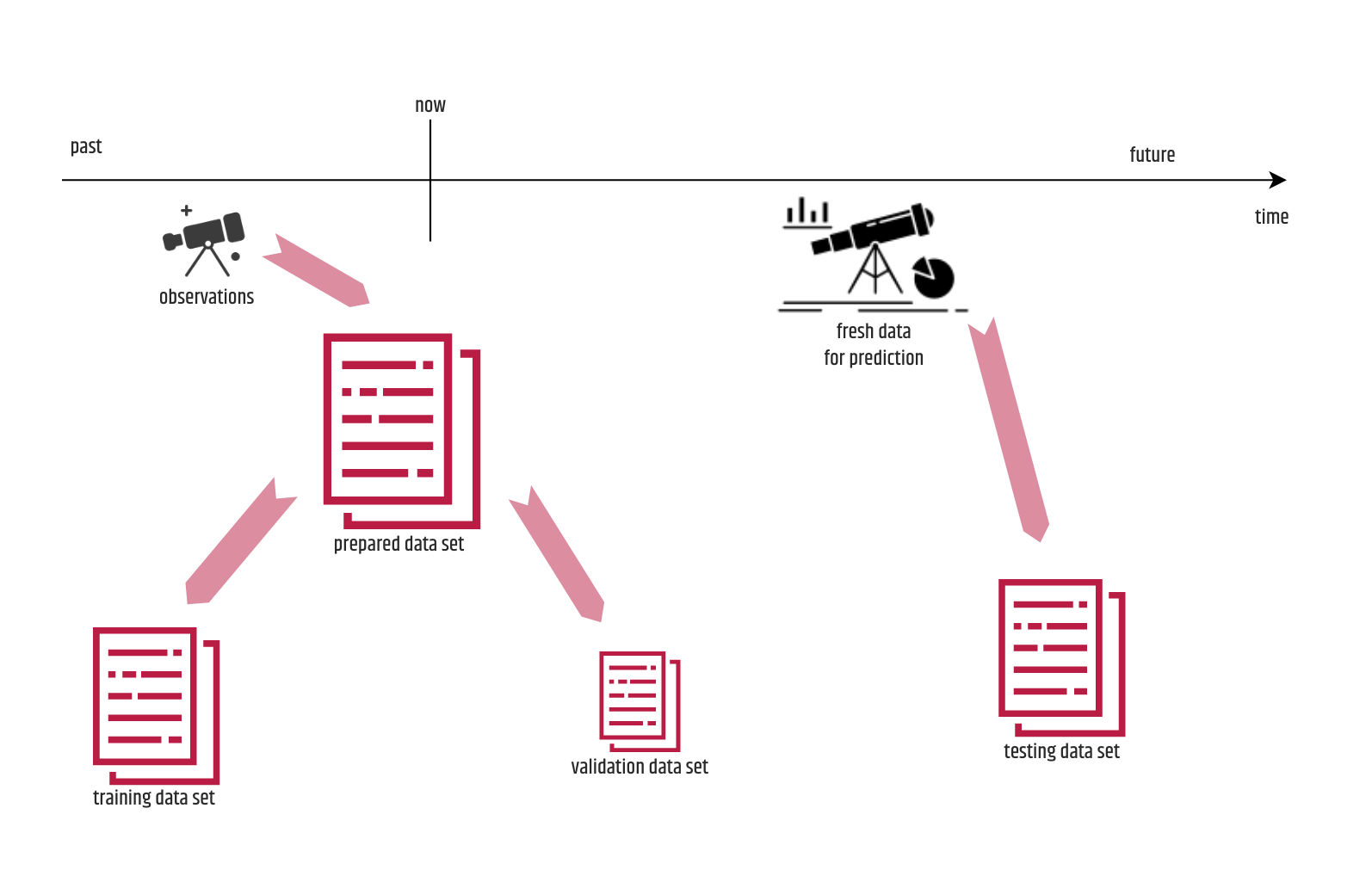
6. Versuchen Sie, unmittelbar nach der ersten Iteration des Trainingsprozesses einen Validierungsprozess zu etablieren. Anfänglich wird es einige Mühe kosten, es zu implementieren, aber später wird es in den meisten Szenarien eine Menge Zeit entweder für die manuelle Validierung oder für unnötige Testverfahren einsparen. Neben dem Einsatz für das Tuning kann es wertvolle Informationen über die Qualität des Trainings liefern und darauf basierende Teamaktionen einleiten. Viele Anfänger betrachten die Validierung in der Regel als eine weitere Form des Testens, was nicht ganz richtig ist. Der für die Validierung verwendete Datensatz ist ein Teil des Datensatzes, der für das Training vorbereitet, aber nicht effektiv für diesen Zweck verwendet wurde. Diese Daten bestehen aus Beobachtungen, die vor dem Training aufgetreten sind, während das Testen mit so genannten frischen Daten durchgeführt wird, die dem trainierten Modell völlig "fremd" sind. Die Train-Validation-Split-Regel, die besagt, dass der Teil des vorbereiteten Datensatzes, der für die Validierung bestimmt ist, immer 15 % betragen sollte, ist nur ein "Mythos", und der Schwerpunkt sollte darauf liegen, dass die Validierungsstichprobe groß genug ist (nicht unbedingt 15 %), repräsentativ ist, verschiedene Werte für ein Merkmal enthält und gleichzeitig gemischt wird. Was die Ausweitung der Validierung betrifft, so ist es vorzuziehen, sie in eine Reihe von Aufgaben aufzuteilen, die der Anzahl der Validierungsregeln entspricht, und diese im Laufe der Zeit schrittweise einzubeziehen. Auf diese Weise können Sie leicht verfolgen, wie sich die einzelnen Regeln auf die Leistung der Abstimmung auswirken.
7. Die Überprüfung des Codes sollte von so vielen Personen wie möglich durchgeführt werden. Die Reviewer müssen nicht unbedingt die Programmiersprache beherrschen, denn wir haben uns darauf geeinigt, ein Team von Generalisten zusammenzustellen. Wenn sie jedoch die Möglichkeit haben, den Code zu sehen, lernen sie die Tricks und den Zweck der Entwicklung im Zusammenhang mit einem bestimmten KI-Prozess kennen und haben eine größere Chance, Korrekturen vorzuschlagen, als dies bei der Standardentwicklung der Fall ist.
8. Die Qualitätssicherung einer KI-Aufgabe wird dringend empfohlen, und die Entwickler sollten diese Rolle nicht übernehmen. Mir ist klar, dass das Testen eines entwickelten Teils eines Prozesses oder einer Phase in einer KI-Pipeline mehr Aufwand erfordert, als wenn eine Qualitätssicherung für eine einfache Entwicklungsaufgabe durchgeführt wird. Dabei müssen nicht nur die Akzeptanzkriterien abgedeckt werden, sondern es muss auch sichergestellt werden, dass die Änderungen nicht die gesamte Pipeline stören, indem die Protokolle währenddessen überprüft werden. Natürlich kann dies für die Personen, die die Tests durchführen, und vielleicht auch für die Produktmanager, die in der Regel die Auslieferung nicht wegen "nur einer weiteren Überprüfung" verzögern wollen, eine große Belastung darstellen. Die Wahrheit ist, dass die Durchführung einer separaten QA die Ausgabevarianten der Pipeline bereichern kann, insbesondere für die Datenaufbereitung und die Modellierungsphasen.
Und schließlich, wenn die Integration nicht funktioniert und Sie mit den bereitgestellten Details nicht einverstanden sind, kann das Projekt mit einer anderen Methodik, aber mit einem anderen Team entwickelt werden, so dass es keine Blockaden oder Störungen gibt, die das Ergebnis verzögern.
Mit anderen Worten...
Obwohl ich versucht habe, die Ausdrücke so anzupassen, dass sie für einen durchschnittlichen Leser geeignet sind, ist mir klar, dass dies vielleicht nicht sehr verständlich war. Deshalb werde ich sie umformulieren und in einer kurzen Zusammenfassung "komprimieren", die den Hauptpunkt dieses Artikels wiedergibt.
Ich verstehe, dass es für jedes Teilgebiet der KI eine steile Lernkurve gibt und dass es nie genug Projekte geben wird, an denen man arbeiten kann, so dass man sagen kann, dass man Fachwissen erreicht hat. Aber scheuen Sie sich auf keinen Fall, Ihre eigenen Ressourcen zu nutzen, wenn Sie ein KI-Projekt in Erwägung ziehen, auch wenn Sie das Gefühl haben, dass sie nicht ausreichen.
In den KI-Gemeinschaften gibt es viele Belege dafür, dass Generalisten genauso viel bewirken können wie Spezialisten. Wenn Sie sich nicht entscheiden können, wie Sie ein Projekt beginnen sollen, können Sie immer die Standard-Arbeitsmethodik in Betracht ziehen. Wenn Sie feststellen, dass ein Prozess oder vielleicht eine ganze Phase nicht anwendbar ist, lassen Sie ihn einfach außer Acht, oder wenn Sie das Gefühl haben, dass Sie einen Knotenpunkt vermissen, der nicht in den üblichen Diagrammen enthalten ist, dann können Sie ihn gerne einführen, aber Sie sollten die Standard-Pipeline als Ausgangspunkt verwenden.
Folglich sollte die Qualität des Projektergebnisses nicht innerhalb bestimmter Fristen garantiert werden, und das ist etwas, was ein Kunde normalerweise verstehen sollte. Ich bin sehr froh, dass Intertec anfängt, in die Richtung zu denken, dass es seinen Kunden anbietet, die Vorteile der Daten, die sie besitzen, zu nutzen und sie für den Vorschlag einer Vielzahl von KI-Lösungen zu verwenden.
Was meine Ingenieurskollegen angeht, die gerade erst anfangen, möchte ich sie natürlich "beschützen", denn realistisch betrachtet sind sie die wichtigsten Rädchen in der KI-Maschinerie. Ich weiß, dass letztlich jeder Entwickler unter Zeit- oder Personaldruck einen Kompromiss eingeht, aber wenn man dazu gezwungen ist, sollte der Kompromiss so erfolgen, dass der Entwicklungsprozess oder die Einhaltung des abgestimmten Arbeitsablaufs nicht gestört wird. Etwas Kluges zu bauen, das etwas Kluges tut" bedeutet, dass man blitzschnelle Ergebnisse erzielen kann, und der Weg, den die Ingenieure dafür zurücklegen müssen, kann lang und holprig sein. Die Befriedigung, die sich danach einstellt, ist jedoch unbezahlbar.