Der folgende Absatz stellt ein Vorwort zu einer Reihe von Artikel-Leitfäden dar, die sich mit kritischen Aspekten des Lebenszyklus von Machine Learning befassen werden. Die Darstellung des Ablaufs eines ML-Projekts an sich ist nicht wichtig - es handelt sich einfach um eine besondere Art von Flussdiagramm. Die Art der Probleme, die mit ML gelöst werden, macht es jedoch schwierig, die entstehenden Projekte ohne einen visuellen Überblick zu verfolgen. In Anbetracht dessen und um den Schwerpunkt auf den ML-Lebenszyklus zu legen, soll dieser Leitfaden nicht nur einen Überblick über die aktuellen Trends und weltweiten Praktiken geben, sondern auch Beispiele aus unserer Erfahrung bei Intertec anführen.
Das Hauptziel der ML-Lebenszyklus-Serie ist es, Einzelpersonen und potenzielle Kunden darüber aufzuklären, wie ML-Projekte zu verstehen sind, und Projektmanagern beizubringen, worauf sie sich konzentrieren sollten, um die Bedürfnisse des Kunden zu befriedigen und so die Aspekte der Erklärbarkeit von Künstlicher Intelligenz zu erreichen.
Überblick über das Problem-Framing
Das Problem-Framing als Anfangsphase des ML-Lebenszyklus wird von den am ML-Projekt beteiligten Teams oft vernachlässigt, insbesondere von den technischen Mitarbeitern, da sie in der Regel erwarten, dass dies von den Stakeholdern oder Managern erledigt werden sollte. Dies ist wahrscheinlich eine Folge der falschen Wahrnehmung dieser Phase als streng geschäftsorientierte Vorbedingung für die Lösung eines bestimmten Problems mit ML. Erschwerend kommt hinzu, dass sich eine unsachgemäße Behandlung dieser Phase negativ auf alle nachfolgenden Phasen auswirken kann, sofern sie danach noch erreichbar sind, und unnötige Zeit- und Ressourcenkosten verursacht. Darüber hinaus spart das Team bei einem erfolglosen Ergebnis (Feststellung, dass keine ML-Lösung angewandt werden kann) als Ergebnis der Problembearbeitung Zeit und Mühe, indem es dasselbe auf die harte Tour herausfindet - während der Arbeit an den nächsten Phasen im Lebenszyklus.
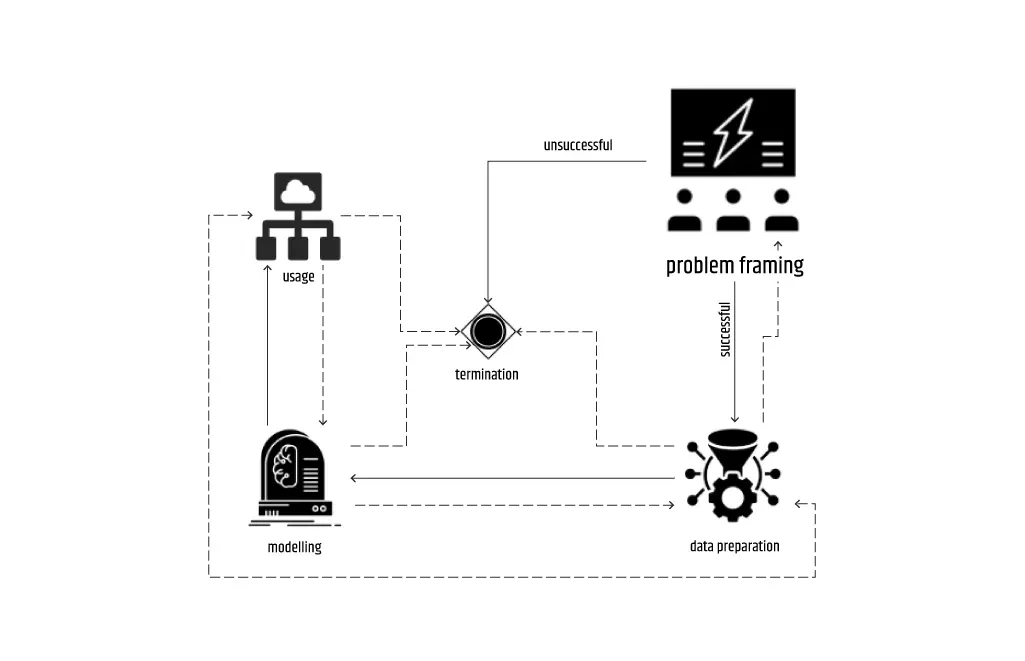
Zu diesem Zweck haben wir bei Intertec.io eine Reihe von Schritten festgelegt, die durchgeführt werden müssen, um das Ergebnis des Problem-Framings genau zu bestimmen. Wir haben auch einen halbwegs strikt definierten Ablauf, bei dem der Prozess des Geschäftsverständnisses immer an erster Stelle steht und die Kostenvorhersage der letzte Prozess ist, bevor die gesamte Phase abgeschlossen wird - wenn sie nicht schon in einigen der vorherigen Prozesse gescheitert ist.

Manchmal kann die Reihenfolge der Prozesse auch anders sein. In einigen Ausnahmefällen kann beispielsweise der Datenermittlungsprozess auf die ML-Bestimmung folgen, wobei ein gewisses Maß an Flexibilität möglich ist, was in der Realität zwar selten vorkommt, aber kein unmögliches Szenario darstellt. Das obige Prozessdiagramm ist eine Zusammenfassung der besten Praktiken der Problemfindung, die ich bisher erlebt habe. Im Folgenden werde ich mich auf die wichtigsten Punkte für jeden der Problemframing-Prozesse konzentrieren.
Geschäftsverständnis
Ich verwende im Vorwort absichtlich den Ausdruck "visueller Überblick", um die visuellen Aspekte beim Diskutieren, Planen oder Analysieren von Dingen im Problemframing zu betonen. Dies ist besonders wichtig für den Prozess des Business Understanding, bei dem entweder eines oder beide der folgenden beiden Szenarien eintreten:
- Das Team trifft sich mit dem Kunden und seinen Anforderungen;
- das Team stellt fest, dass es dem Kunden aufgrund der Zugänglichkeit seiner Ressourcen eine ML-Lösung anbieten kann.
Während des Gesprächs mit den Vertretern des Kunden ist es wichtig, die wichtigsten Punkte zu notieren, um die eigenen Gedanken im Nachhinein zusammenzufassen. Es dient auch als Grundlage für weitere Brainstorming-Sitzungen. Neben dem Abgleich und der Anpassung der Terminologie ist der wichtigste Teil dieser Sitzungen der Gedankenaustausch darüber, wie ein Einzelner das Problem versteht und wie das Team es verstehen sollte.
Eine Tätigkeit, die keine großen Fähigkeiten erfordert und deshalb wahrscheinlich übersehen wird, ist das Verstehen von Prozessablaufdiagrammen. Für die gängigsten Diagrammwerkzeuge wie Diagrams oder Lucidchart gibt es nicht viele kostenlose Symbole speziell für den ML-Lebenszyklus, und ich würde nicht empfehlen, mehr Zeit mit der Suche nach den geeignetsten zu verbringen. Stattdessen wird die Auswahl der selbsterklärenden Icons das Vorgehen vereinfachen, abgesehen davon, dass Sie Ihr eigenes wiederverwendbares Set erstellen. Zur Veranschaulichung: Die Diagramme im vorherigen Abschnitt wurden mit Diagrams erstellt und die folgenden Diagramme mit Whimsical, das von Doug Hudgeon, einem der Autoren des Buches Machine Learning for Business, vorgeschlagen wurde.
Dieses Verständnis durch die Erstellung von Diagrammen hilft dem Team bei der Definition des Problems und seiner möglichen Lösung durch den Einsatz von ML. Eine korrekte Problemdefinition liefert in der Regel das Ergebnis des Geschäftsverstehensprozesses. Es gibt drei mögliche Ergebnisse für ein angesprochenes Problem.
Nicht ML-lösbar
Manchmal gibt es Probleme, die mit den derzeitigen Technologien und Methoden nicht mit ML gelöst werden können. Einen ersten Anhaltspunkt, ob etwas lösbar ist, liefert das folgende Diagramm. Wenn jeder der Schritte, die als manuell angesehen werden, einfach nicht von einer Maschine ausgeführt werden kann, wird in der Regel festgestellt, dass die Lösung des Problems mit ML unmöglich ist.
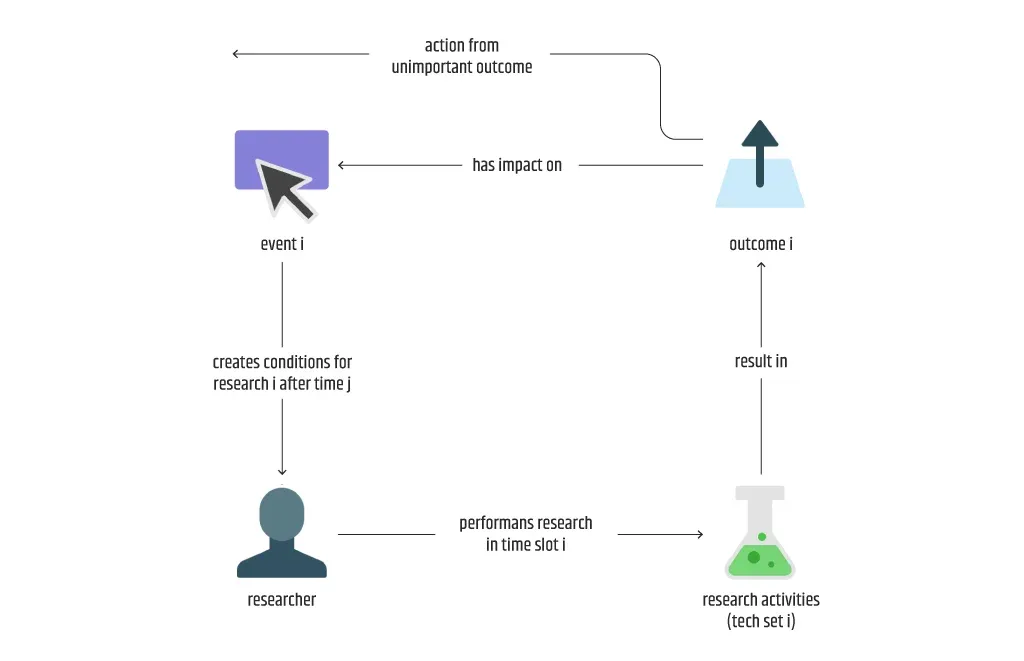
Andere Kandidaten können Probleme sein, die sich nicht oft genug wiederholen, wenn sie durch ein zufälliges Ereignis ausgelöst werden oder wenn die Häufigkeit der Aktionen gering ist oder nicht vorhergesagt werden kann. Beispielsweise kann jede technische Forschungsaktivität, bei der je nach Technologie eine Vielzahl von Methoden zum Einsatz kommt und die nicht repetitiv ist, durch ein Ereignis ausgelöst werden, das schwer vorherzusehen ist und normalerweise selten auftritt.
Schließlich gibt es Probleme, die für ML-Lösungen gar nicht in Frage kommen. Diese Fälle treten häufig auf, wenn das Team der Initiator einer Lösung für ein Problem ist, das ein Kunde wahrscheinlich schon hat. Ein solches Beispiel ist das Angebot eines konversationellen Chatbots für ein kleines Unternehmen, das Chatdienste nur intern nutzt.
ML-lösbar
Probleme, die unabhängig von der Domäne definitiv als ML-lösbar eingestuft werden können, fallen in der Regel unter die folgenden zwei Kategorien in Bezug auf die Geschäftsprozesse:
Automatisierung - sich wiederholende zeitaufwändige Prozesse oder Prozesse, die anfällig für menschliche Fehler sind;
Vorhersage - Prozesse, die von Werten profitieren, die nicht einfach vorhergesagt werden können.
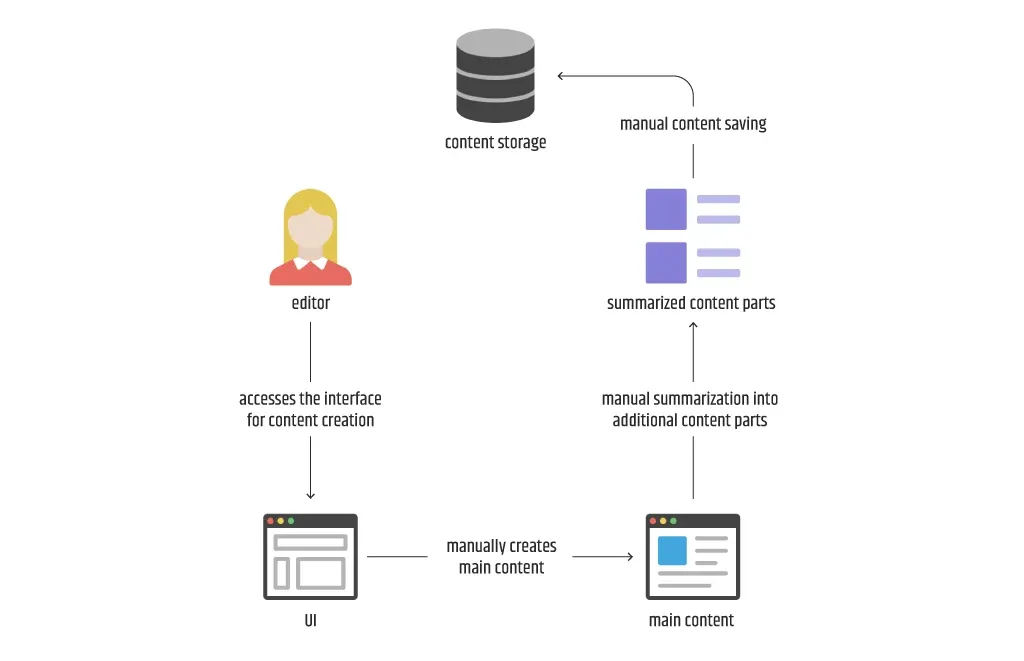
Kehren wir zu dem Diagramm zurück, das den manuellen Prozess der Inhaltserstellung unter Beteiligung eines Redakteurs erläutert. Wie lässt sich konkret feststellen, ob ein Problem mit ML lösbar ist? Ganz einfach, indem man sich auf das Diagramm zum Geschäftsverständnis bezieht. Wenn mindestens eine der als manuell gekennzeichneten Aktionen automatisiert werden kann, kann das Team mit den nächsten Prozessen des ML-Lebenszyklus fortfahren.
Betrachten Sie das Diagramm, das die Erstellung von Inhalten durch einen Redakteur beschreibt. Dies ist ein guter Kandidat für die Verbesserung des automatisierten Prozesses, da mindestens eine der Aktionen manuell ist und auf verschiedene Weise durchgeführt werden kann: durch reine Texterstellung des Hauptinhalts, durch Zusammenfassung des Hauptinhalts, durch Erstellung + Zusammenfassung oder sogar durch vollständige Automatisierung des gesamten Prozesses, ohne dass ein Redakteur als Benutzer des derzeitigen Inhaltserstellungssystems erforderlich ist.
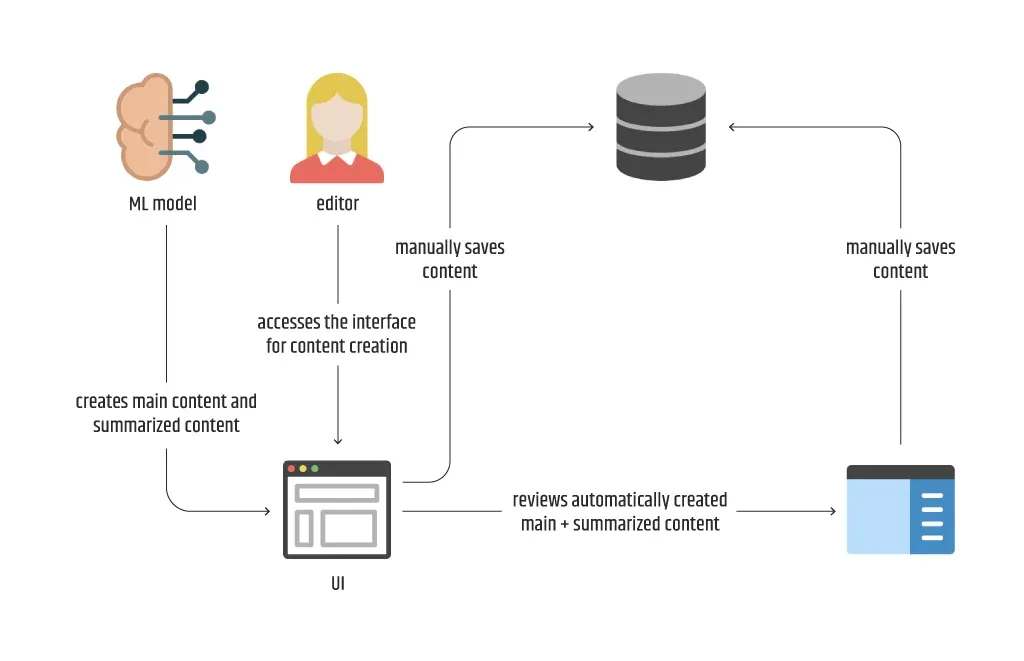
Da es manchmal mehrere Möglichkeiten gibt, ein bestimmtes Problem mit ML zu lösen, wie im vorherigen Beispiel, sollte die Vorgehensweise mit dem Kunden ausgehandelt werden. Es ist jedoch wichtig, alle Optionen auf den Tisch zu legen und so offen wie möglich zu sein, denn manchmal ist sich der Kunde nicht aller Möglichkeiten bewusst. Zum Beispiel wollte der Kunde vielleicht nur das Schreiben des Hauptinhalts lösen und hat die Zusammenfassung überhaupt nicht in Betracht gezogen.
Wahrscheinlich ML-lösbar
Einige Probleme können als ML-lösbar eingestuft werden, allerdings nur unter bestimmten Bedingungen. Diese Bedingungen spiegeln sich in der probabilistischen Natur der ML wider, bei der der Kunde in Abhängigkeit von der erreichten Genauigkeit eine Entscheidung darüber treffen muss, ob das Problem als lösbar eingestuft werden soll oder nicht. In lebenswichtigen Fällen wie der Fähigkeit des Modells, Straßenschilder für selbstfahrende Fahrzeuge zu erkennen, ist eine Erkennungsrate von 99 % möglicherweise nicht ausreichend.
Da wir uns bei Intertec.io mit nicht lebensabhängigen ML-Problemen befassen, akzeptieren die Kunden manchmal eine anfängliche Genauigkeit unserer Modelle von nur 60 %, selbst für Produktionszwecke, da einige der Modelle zu Vorschlagszwecken verwendet werden. Der Kunde kann oft sehr genau angeben, wie hoch die erwartete Mindestgenauigkeit einer Lösung sein soll, aber die Realität sieht so aus, dass das Team dies aufgrund des bereits erwähnten Wahrscheinlichkeitsaspekts nicht immer garantieren kann, insbesondere bei höheren Werten (über 90 %). Was ausgehandelt werden kann, ist der Zeitraum, in dem das Modell ausgefeilt wird. Ein gutes Beispiel hierfür ist "das Modell innerhalb eines Monats von 70 % auf 75 % zu verbessern".
Je nach Entscheidung des Kunden, die sich in der Regel aus der Perspektive ergibt, kann ein Problem auch mit ML gelöst werden, wenn diese Perspektive auch mit der Sichtweise des Teams übereinstimmt. Schauen Sie sich zum Beispiel das folgende Diagramm an, das ein Problem bei der Erstellung von Newslettern beschreibt. Das Team ist zuversichtlich, dass es die Erstellung des Newsletters mit ML vollständig automatisieren kann, da eine effiziente Methode zum Schreiben einer Zusammenfassung des Sprachinhalts implementiert werden kann. Der Kunde ist jedoch damit zufrieden, nur einige wenige Vorlagen für diesen Zweck zu haben, und legt keinen Wert auf die Kreativität beim Schreiben. Daher bringt der zusätzliche Aufwand für die Verwendung eines Zusammenfassungsmodells in den Augen des Kunden keinen Mehrwert, was zu einer partiellen NL-Generierung (nur für den Inhalt mit den Schlüsselinformationen) anstelle einer vollständigen automatisch generierten NL ohne manuelle Eingriffe führt.
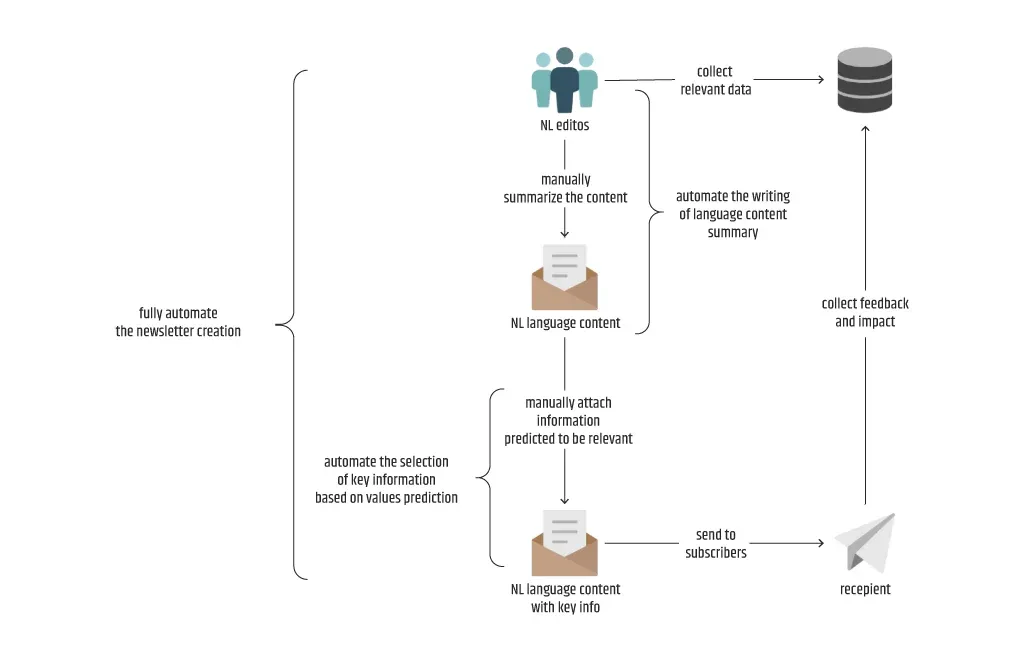
Manchmal ist die mangelnde Verfügbarkeit geeigneter Technologien ein Schlüsselfaktor für die Wahrscheinlichkeit, dass das Problem mit ML gelöst werden kann. Hätte man sich vor Jahren mit dem Problem der NL-Erstellung befasst, bevor die Transformers-Architektur zusammen mit der Verfügbarkeit einer großen Anzahl von vortrainierten Modellen in Verbindung mit den Transfer-Learning-Konzepten zur Verfügung stand, wäre der Aufwand zur Lösung des Problems mit herkömmlichen NLG-Methoden erheblich größer und das Ergebnis ungewiss gewesen.
Die beste Vorgehensweise, wenn das Ergebnis dieses Geschäftsverstehensprozesses wahrscheinlich ML-lösbar ist, besteht darin, weitere Untersuchungen durchzuführen, die mehr Zeit in Anspruch nehmen, wovon der Kunde Kenntnis haben muss und oft einen Rückzieher machen kann, da dies zeitlich und finanziell zu kostspielig ist.
Datenermittlung
Dieser Prozess beginnt damit, dass der Kunde gefragt wird, ob er über qualitative und quantitative Daten im Zusammenhang mit dem Geschäftsproblem verfügt. In Anlehnung an die Praxis des Verstehens durch Diagramme ergibt sich die Frage nach der Datenverfügbarkeit als direkte Folge des Fehlens eines Symbols, das mit irgendeiner Art von Datenspeicherung verbunden ist. Selbst die Verfügbarkeit von scheinbar nützlichen Daten bedeutet nicht, dass eine ML-Lösung garantiert ist.
Ein negatives Ergebnis dieses Prozesses hängt von der Bereitschaft des Kunden ab, mehr zu investieren, wenn nicht genügend Daten im geeigneten Format vorhanden sind. Wenn der Kunde zögert, sollte das Team in der Regel darauf drängen, geeignete Datenquellen zu finden und nicht sofort aufgeben. Das Problem besteht darin, dass diese zusätzlichen Maßnahmen zur Ermittlung relevanter Datenquellen die Freigabefristen drastisch verlängern und damit die Projektkalkulation erheblich beeinträchtigen können. Auch die mögliche Gefahr einer personellen Unterbesetzung sollte in Betracht gezogen werden.
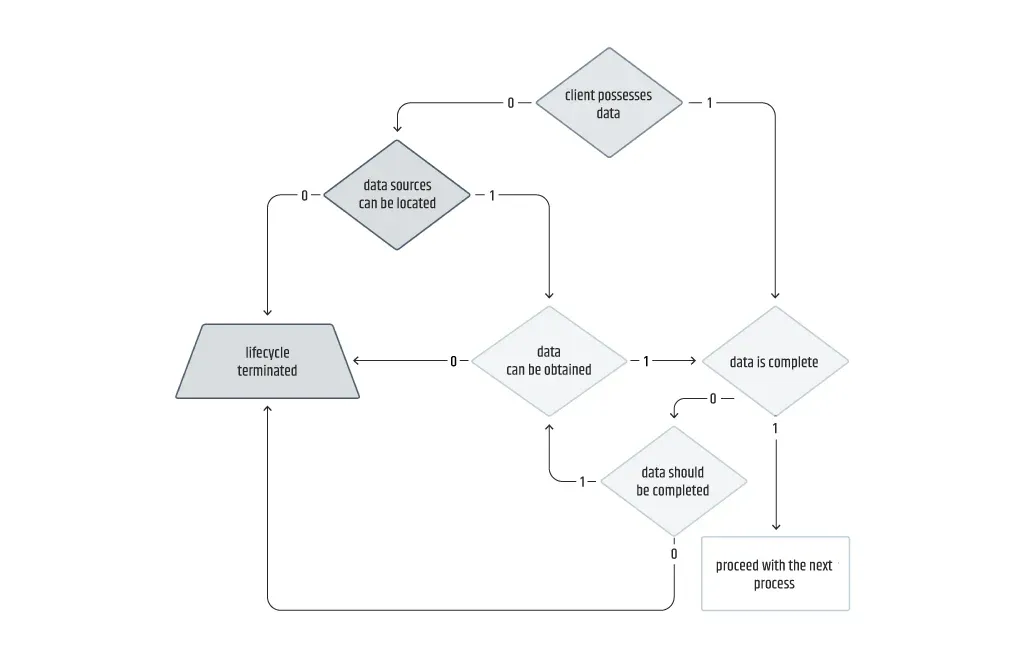
Ausgehend von den Erfahrungen unseres Unternehmens und unseres Teams werde ich versuchen, die Datenverfügbarkeit in vier Kategorien zusammenzufassen.
Nicht verfügbare Datenquellen
Diese Kategorie umfasst das schlimmstmögliche Szenario, bei dem es keine Quellen gibt, aus denen die Daten bezogen werden können, oder deren Standorte unbekannt sind. Wenn Sie den ML-Lebenszyklus nach diesem Szenario nicht beenden, bedeutet dies, dass die einzige Möglichkeit zum Fortfahren darin besteht, die Daten manuell zu erstellen. Dies ist eines der größten Risiken bei der Durchführung von Maßnahmen und sollte daher sorgfältig abgeschätzt werden.
Wenn die Hypothese besteht, dass potenzielle Datenquellen vorhanden sind, kann das Team mit Zustimmung des Kunden auch eine Crawl-Methode anwenden. Dies kann viel Zeit in Anspruch nehmen, und bis zu seinem Abschluss sollten die anderen Aktivitäten blockiert werden.
Nicht verfügbare Daten
Auch wenn der Name dieser Kategorie ähnlich lautet wie der der vorherigen, besteht hier zumindest die Möglichkeit, die Standorte geeigneter Datenquellen zu ermitteln. Wenn diese Quellen erfolgreich identifiziert wurden, sollten die Daten mit Techniken wie Verschrottung, Scannen, Konvertierung usw. beschafft werden. Auch dies ist ein riskanter Schritt, da es keine festen Garantien für die Ergebnisse der genannten Techniken gibt und daher mit Vorsicht zu genießen ist.
Unvollständige Daten
Es gibt Szenarien, in denen das Team einen Teil der Daten identifiziert. Wenn diese jedoch unvollständig sind, sind sie für das Projekt unbrauchbar. Fehlende Beschriftungen sind einer der häufigsten Fälle, die verhindern, dass die Daten für ML-Lösungen verwendet werden können, und in den meisten Fällen kommt manuelle Beschriftung zur Rettung.
Zum besseren Verständnis möchte ich eine persönliche Erfahrung schildern, die ich bei dem Versuch gemacht habe, ein Problem der Mitarbeiterklassifizierung anhand von Lebensläufen und zusätzlichen Inhalten zu lösen. Der Kunde hatte eine einzigartige Art und Weise, die Stellenbeschreibungen des Unternehmens zu definieren, die nicht einfach mit gescrapten Daten abgeglichen werden können. Da das Unternehmen nicht über ausreichende Mengen an eigenen Daten verfügte, war die manuelle oder halbautomatische Kennzeichnung (ggf. unter Verwendung von Token-Matching-Kriterien) ein erster Schritt, um eine beträchtliche Menge an Daten für die nächste Phase zu erhalten.
Es ist wichtig, darauf hinzuweisen, dass manchmal nicht nur die Beschriftungen fehlen, sondern auch andere Teile der Daten, was oft zusätzliches Scraping oder andere manuelle Eingriffe erfordert.
Vollständige Datenverfügbarkeit
Dies ist das bestmögliche Ergebnis des Datenermittlungsprozesses, das sich deutlich (ohne viele Überraschungen) auf die nächsten Prozesse auswirkt. Denken Sie daran, dass ich hier nur auf die Verfügbarkeit von Rohdaten hinweise. Andere Techniken wie z. B. Datenumwandlungsschritte kommen später in der Datenvorbereitungsphase.
ML-Typ-Bestimmung
Dieser Prozess ist eine Folge des erfolgreichen Ergebnisses des Geschäftsverständnisses und der Datenermittlung, obwohl in einigen Fällen das Ergebnis bereits während des Fortschritts beider Prozesse erahnt werden kann. Das Erkennen des ML-Typs ist eine Sache, aber die korrekte Bestimmung ist eine andere, denn dazu müssen alle Kandidaten auf den Tisch gelegt und der vielversprechendste ausgewählt werden. Das scheint einfach und unkompliziert zu sein, aber dieser Prozess ist manchmal fehleranfällig.
Nehmen wir an, das Team hat alle Daten, die es braucht, um mit der Arbeit an dem Problem zu beginnen. Auf den ersten Blick scheint klar zu sein, was der Output des Modells sein soll oder was der Kunde verlangt. Manchmal gibt es jedoch auch andere Output-Kandidaten, die vom Kunden übersehen werden, was in der Regel geschieht, wenn das Team das Problem und damit die Lösung anders wahrnimmt. Schauen wir uns die beiden folgenden Beispiele an.
Im ersten Beispiel konzentriere ich mich nur auf die Lösung für die automatische Auswahl von Schlüsselinformationen in den NL aus dem wahrscheinlich mit ML lösbaren Teilbereich. Das Geschäftsverständnis hat gezeigt, dass die Schlüsselinformationen auf der Grundlage eines manuellen Gefühls für den Ertrag, den sie dem Kunden bringen, ausgewählt werden. Darüber hinaus gibt es nach dem Datenfindungsprozess eine riesige Menge an historischen Daten, die die Einnahmen für jede Schlüsselinformation enthalten. Obwohl es sich also um ein einfaches binäres Klassifizierungsproblem mit der Auswahl als Etikett handelt, kann es auch durch eine Regression gelöst werden, wenn das Etikett die Einnahmen selbst darstellt. Auch wenn der zweite Ansatz potenziell komplizierter ist, eignet er sich besser als Lösung, da die manuelle Auswahl die Einnahmen in der Regel nicht mit großer Genauigkeit vorhersagen kann.
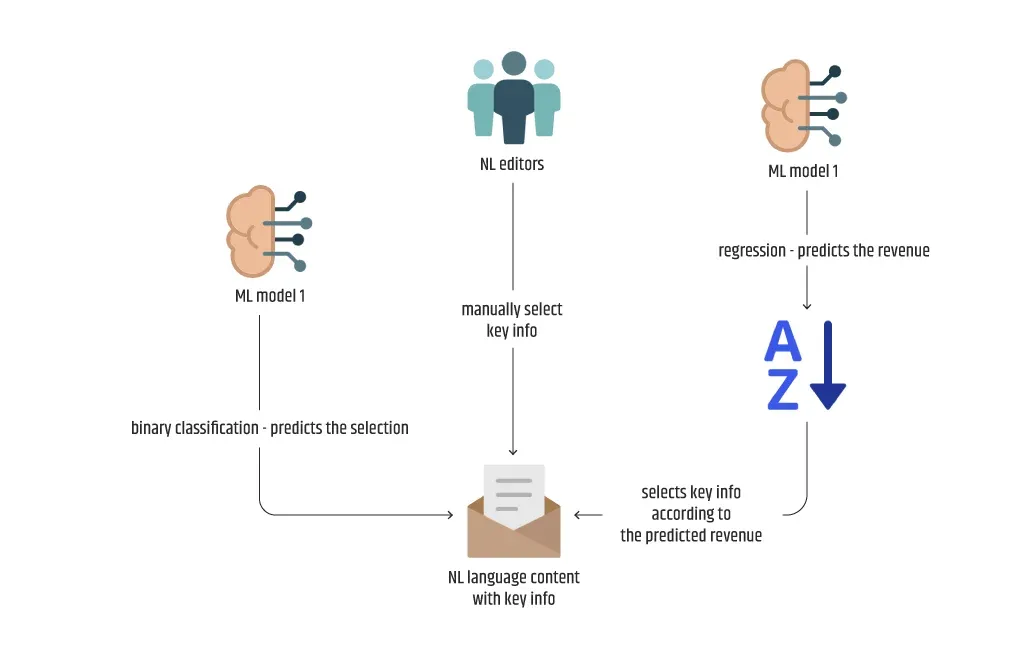
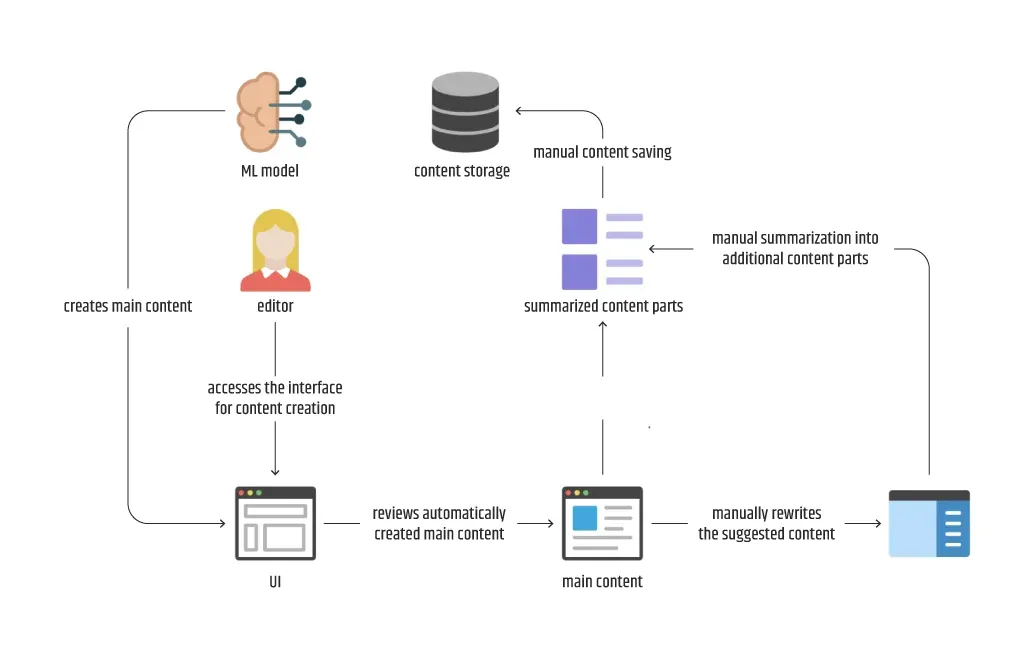
Was das andere Beispiel betrifft, so sehen wir uns das zweite Diagramm an, das im Unterabschnitt ML lösbar vorgestellt wurde. Hier müssen wir einen Weg finden, um das Problem der Generierung von zwei getrennten Inhaltsteilen zu lösen - den Haupt- und den zusammengefassten Inhalt. Anhand der gefundenen Daten erklärt ein Teammitglied, dass beide Inhaltsteile aus einem einzigen Satz von Merkmalen generiert werden können, während ein anderes meint, dass zwei Arten von Modellen verwendet werden sollten, die sich ausschließlich mit einem Inhalt befassen. Dieses Mal sprechen wir nicht von "klassischen" ML-Typen, sondern von NLP oder genauer gesagt von verschiedenen NLG-Typen. Separate Frameworks, Formate und Größen sollten dabei nicht zur Diskussion stehen. Stattdessen sollten wir uns mit den am besten geeigneten Kandidaten je nach Modelltyp befassen. Daher sollte weniger über Pytorch vs. Tensorflow oder GPT-2 vs. DistilGPT-2 vs. T5 gesprochen werden, sondern mehr über text2text, seq2seq und Zusammenfassung.

Noch einmal: Das Ergebnis dieses Prozesses muss nicht unbedingt auf einen ML-Typ oder ein ML-Modell beschränkt sein, sondern auf eine Reihe von Kandidaten. Es ist jedoch zu beachten, dass bei mehr als einem Vorschlag im Vorfeld ein zusätzlicher Zeitraum eingeplant werden sollte, um einen Puffer für die Rückgewinnung einer nicht zufriedenstellenden Auswahl zu haben.
Planung der Infrastruktur
In diesem Prozess wird nicht nur die Infrastruktur, sondern auch die potenzielle Nutzung jeder in Frage kommenden Technologie als Teil der Lösung geplant. Der Schwerpunkt liegt auf der Infrastruktur, da sie anfällig für architektonische Flexibilität ist und den größten Einfluss auf den nächsten Prozess der Problemframing-Phase hat. Die Infrastruktur kann anhand der vom Kunden erhaltenen Antworten festgelegt werden oder vom Team selbst entschieden werden, wenn der Kunde nicht stark an eine bestimmte Infrastruktur gebunden ist, die er geerbt hat oder einführen möchte.
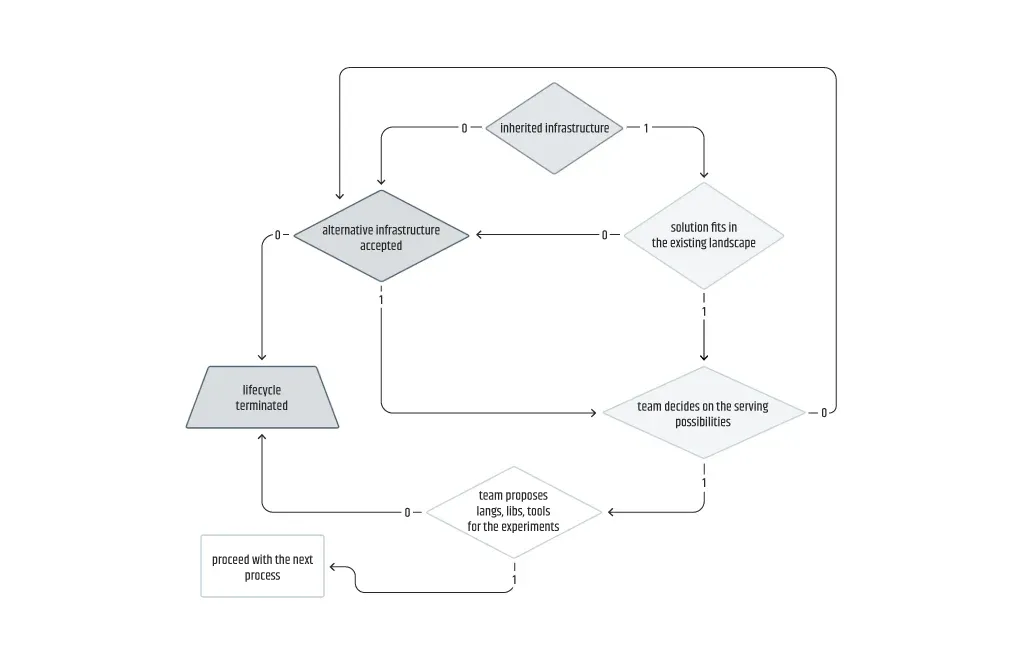
Jedes Team sollte sich bemühen, während dieses Prozesses Antworten auf eine Reihe wichtiger Fragen zu erhalten. Es wird empfohlen, mit den Fragen zu beginnen, die hauptsächlich vom Kunden abhängen, z. B. über eine mögliche bestehende Infrastruktur, und dann mit den Fragen abzuschließen, die hauptsächlich vom Team selbst abhängen. Ein Beispiel für eine Reihe von Fragen sind die folgenden (es empfiehlt sich, die Reihenfolge einzuhalten, obwohl die letzte Frage normalerweise unabhängig behandelt werden kann und der Vorschlag des Teams im Extremfall nicht akzeptiert wird):
- Wie fügt sich die Lösung in die bestehende Umgebung ein, falls eine Infrastruktur übernommen wird?
- Welche Technologie soll für die Bereitstellung der Modelle verwendet werden?
- Wo soll die Lösung gehostet werden?
- Welche Sprachen, Bibliotheken und Werkzeuge sollen für die Experimente verwendet werden?
Da es mehrere Kandidaten für die Infrastruktur und das Hosting/Serving geben kann, kann die Planung verhandelbarer sein, da sie von der Sicht des Kunden und der Vererbung abhängt. Beispielsweise möchte ein Kunde für einen ML-Typ zur Zeitreihenprognose die Lösung auf AWS statt auf GCP hosten, weil er diese Cloud-Plattform bereits übernommen hat. Wenn das Team daraufhin vorschlägt, die Modelle mit Sagemaker bereitzustellen, ist der Kunde möglicherweise nicht ganz zufrieden mit der Anzahl der erforderlichen manuellen Eingriffe. Schließlich schlägt das Team eine begrenzte, aber stärker spezialisierte Alternative in Forecast vor, die für den Kunden akzeptabel ist.
Im Allgemeinen ist es für ein Team wünschenswert, dass die Software so viel Spielraum wie möglich hat, insbesondere wenn es sich um Open-Source-Software handelt. Bei der Planung sollte ein Minibericht darüber erstellt werden, ob ein bestimmtes Teil ein anderes unterstützt (unterstützt DVC S3 als Ziel für die versionierten Assets) oder sich mit einem überschneidet (speichert MLFlow Modellartefakte auf ähnliche Weise wie DVC). Ein nützliches Konzept zur Darstellung der Beziehungen zwischen verschiedenen Softwareteilen wird im C4-Modell vorgeschlagen, für das ich die Verwendung des IcePanel als vollständiges Werkzeug oder des C4-Shape-Sets von Diagrams empfehle, wobei die Shape-Ebene:
- Der Kontext repräsentiert das gesamte Softwaresystem (der fehlende und der vererbte Teil);
- der Container wird verwendet, um alle Teile zu definieren, die unabhängig als APIs, MLOps-Plattformen oder Speicher funktionieren können;
- die Komponente kann geeignet sein, organisierten Code wie Notebooks und Skripte oder separate Assets wie Modelle und Datensätze zu beschreiben;
- Code sollte verwendet werden, um auf wichtige Codeschnipsel oder Notizbuchzellen hinzuweisen.
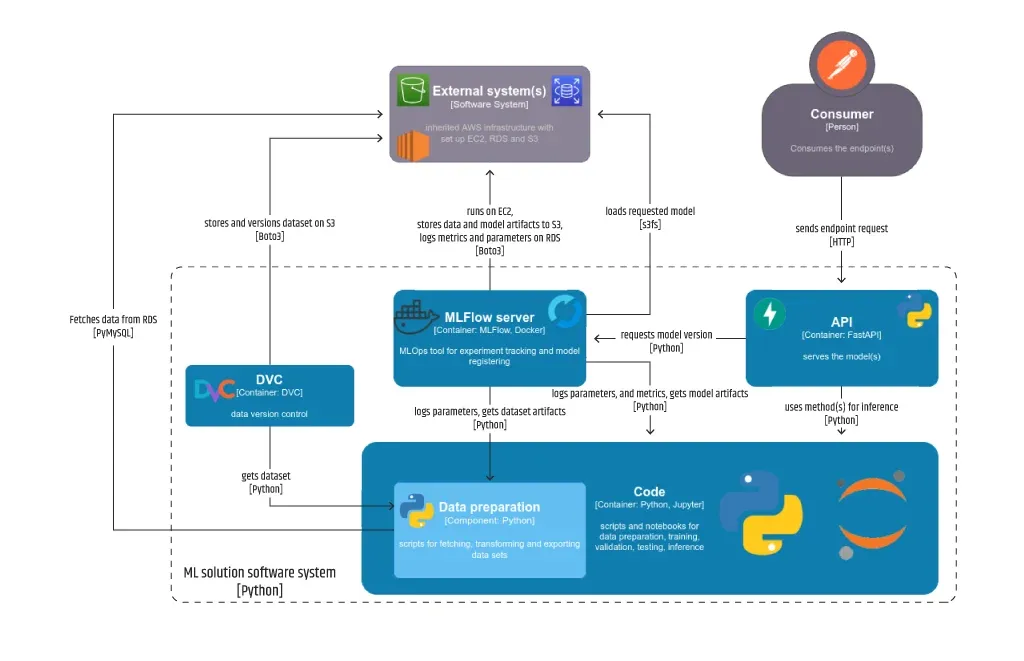
Die Erfahrung von Intertec.io zeigt, dass die Entkopplung von Datensätzen, Modellen, Diensten, Experimenten (Training/Feinabstimmung, Validierung, Tests) und Nachverfolgung tatsächlich die beste Praxis für eine architektonische Lösung ist. Der erste Eindruck könnte sein, dass dies nicht ganz optimal ist, da DVC auch für die Modellversionierung verwendet werden kann, aber da MLFlow dies auf eine Weise handhabt, die für die beteiligten Personen besser geeignet ist, hat sich das Team entschieden, beide Lösungen zu verwenden.
Kostenvorhersage
Ich werde hier nicht beschreiben, wie man ein Modell zur Vorhersage der Kosten für die Implementierung einer ML-Lösung trainiert. Obwohl der Titel dieses Prozesses irreführend zu sein scheint, möchte ich Sie gleich darauf hinweisen, dass sich der Begriff Kosten nicht nur auf Geld bezieht, sondern auch auf alle anderen Aspekte des Ressourceneinsatzes, wie Zeit und Personal. Die Kosten werden auch in den vorangegangenen Prozessen berücksichtigt, aber in einem kleineren Rahmen.
In diesem Prozess hat das Team die Möglichkeit, den gesamten Projektplan zu überprüfen und gegebenenfalls einige Anpassungen vorzunehmen oder den Lebenszyklus zu beenden. Beide Seiten sollten sich darüber im Klaren sein, dass der Schätzungsprozess aufgrund der Komplexität des ML-Lebenszyklus, der im Vergleich zu anderen standardmäßigen Softwareentwicklungsabläufen zu mehr Iterationen und Kreativität neigt, mit Vorsicht angegangen werden sollte. Natürlich ist es mir nicht möglich, in diesem Abschnitt ein vollständiges und detailliertes Beispiel zu geben. Stattdessen werde ich versuchen, einige Schlüsselpunkte zusammen mit kleineren Beispielen pro Lebenszyklusphase zu erwähnen, wobei ich die offensichtlichen (und in der Regel quelloffenen/freien) technischen Entscheidungen wie Programmiersprachen und Frameworks außer Acht lasse.
Bei der Vorbereitung von Datensätzen für die Modellierung möchte das Team in der Regel den bestmöglichen Datensatz exportieren. Selbst bei einer kleinen Anzahl von Datenquellen kann es schwierig sein, diesen Schritt ohne eine Pipeline häufig zu wiederholen, was oft die Inanspruchnahme einiger verwalteter Dienste erfordert, die relativ teuer sind. Ist es immer notwendig, Datenaufbereitungspipelines zu erstellen? Unwahrscheinlich, denn wenn die Trainingshäufigkeit gering ist und ein geringes Risiko von Datendrifts besteht, gibt es keinen triftigen Grund, die manuelle Aufnahme durch eine automatisierte Pipeline zu ersetzen.
Was die Modellierungsphase angeht, so kann die Menge der Modellkandidaten, die zuvor im ML-Typ-Bestimmungsprozess ausgewählt wurde, weiter herausgefiltert werden, wenn die potenziellen Kosten analysiert werden, die jeder von ihnen mit sich bringt. Hier geht es um die Analyse der Kosten von drei Ansätzen (Lex-Dienst eines Drittanbieters, eigene trainierte DialoGPT, eigene fein abgestimmte DialoGPT) für die Lösung eines Konversationsproblems, wobei die Schlüsselkriterien verglichen werden, wobei die Farbe die relative Höhe der Kosten angibt (grün ist die niedrigste, rot die höchste).
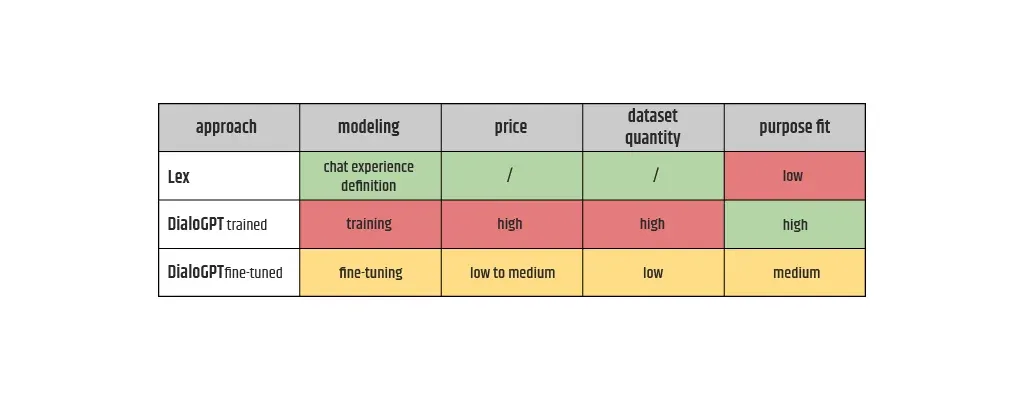
Die Kosten für die Kriterien Preis und Zweckmäßigkeit sind verallgemeinert, was bedeutet, dass die Schätzungen in seltenen Fällen völlig gegensätzlich sein können. Die Zweckmäßigkeit kann erst viel später im Lebenszyklus während des Testprozesses überprüft werden, wenn die Qualität der Ausgabe zusammen mit der Latenzzeit auf demselben Datensatz verglichen werden kann. Die Vorteile des Transfer-Learning-Konzepts ermutigen das Team in der Regel dazu, der Feinabstimmung der Modelle Vorrang vor dem Rest zu geben, da der Aufwand in der Modellierungsphase im Vergleich zum Training von Grund auf geringer ist und die Anpassung an den Zweck besser ist als bei den verwalteten Diensten wie Lex. Eine ähnliche Vergleichstabelle kann für andere NLP-Ansätze wie die Zusammenfassung erstellt werden. Für andere ML-Typen, die nicht zur NLP gehören, können die Kriterien unterschiedlich sein.
In der letzten Phase des ML-Lebenszyklus fallen Kosten für den Betrieb des Modells in der Produktion an. Dies bedeutet, dass die Kosten für die Dienste/APIs und die Überwachung/Beobachtbarkeit geschätzt werden müssen. Es ist gut, einen Dienst zu nutzen, der die Bereitstellung verwaltet und mit Gleichzeitigkeit umgehen kann, wie z. B. Sagemaker, aber die Nutzung dieses Dienstes kann oft teuer werden, insbesondere bei Modellen, die größere Instanzen für den Betrieb benötigen. In Fällen, in denen der Output des Modells nicht direkt von einem Endbenutzer verbraucht wird, d. h. die Latenzzeit kein großes Problem darstellt, ist die Verwendung einer containerisierten API auf einer kleineren Instanz eine kostengünstigere Option.
Es sind zusätzliche Kosten zu berücksichtigen, die globaler sind als die zuvor genannten. Da MLOps noch kein anerkannter Standard in der ML-Branche ist, sind die Kunden in der Regel nicht sehr daran interessiert, die Vorteile zu verstehen. Neben den Vorteilen, die sich aus der Übernahme des Großteils der ML-Lebenszyklusprozesse durch das Team ergeben, kann die Offenlegung der Experimentverfolgung für den Kunden bedeuten, dass die Anforderungen an die Erklärbarkeit von KI erfüllt werden. Daher muss der Kunde über die Existenz des MLOps-Tools informiert werden, das ohne Kompromisse eingesetzt werden sollte.
Die Kostenreduzierung für den Kunden nach dem Einsatz der Lösung sollte nicht daran gemessen werden, wie viele manuelle Tätigkeiten sie ersetzt. Das liegt nicht daran, dass man eine Revolte unter den Menschen vermeiden will, "deren Arbeit möglicherweise von den Maschinen übernommen werden kann", sondern an der Erwartung, dass diese Menschen die ersten Bewerter der Aktivitäten der Modelle werden, was insbesondere für ML-Typen gilt, die keine genaue Validierung durchführen können, wie z. B. die Erzeugung natürlicher Sprache.
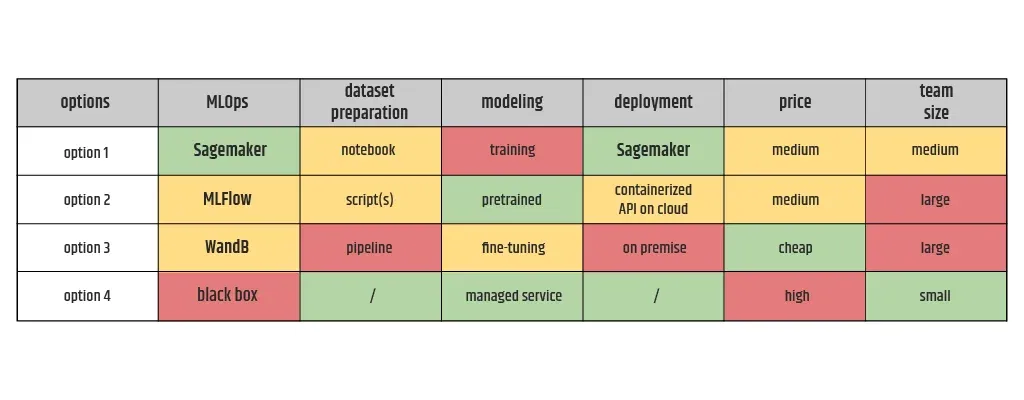
Das Endergebnis des Prozesses der Kostenvorhersage liegt nicht in Form eines Diagramms, sondern in Form einer Tabelle vor, die mehrere Optionen für die Umsetzung enthält, wobei der Schwerpunkt auf den Kosten für jedes Schlüsselkriterium liegt. Eines der Schlüsselkriterien ist die Größe des Teams und seine Struktur, die von einer Option zur anderen variieren kann und mit den meisten der anderen Kriterien korreliert. Diese Tabelle sollte die Vorteile einiger Optionen gegenüber den anderen pro Kriterium aufzeigen, denn wenn es keine klaren Argumente für oder gegen eine Auswahl gibt, sollte sie dem Kunden zur endgültigen Entscheidung vorgelegt werden.
Abschließende Überlegungen
Ich habe versucht, den Inhalt der vorangegangenen Abschnitte so weit wie möglich zu komprimieren", d. h. es gibt noch weitere Konzepte zu erwähnen und weitere Beispiele zu nennen. Lassen Sie mich versuchen, Antworten auf einige der offensichtlichen Fragen zu geben und meine abschließende Schlussfolgerung zum Thema zu formulieren.
Welche Teammitglieder auf Seiten des Unternehmens sollten an den Diskussionen zur Problemstellung teilnehmen?
Wenn möglich, sollten alle für das Projekt vorgesehenen Teammitglieder an den ersten Besprechungen teilnehmen. Neben dem Produktmanager und anderen Mitarbeitern in Standardrollen wie DevOps oder QA sind die entscheidenden Rollen ein Datenanalyst, ein Data Engineer und ein Data Scientist, insbesondere in den Prozessen der Data Discovery, der Infrastrukturplanung bzw. der ML-Typenbestimmung. Die Seniorität der beteiligten Personen ist wünschenswert, aber kein Muss, denn manchmal können die jüngeren Teammitglieder über den Tellerrand hinausschauen und unerwartet zum Brainstorming beitragen.
Gibt es Entwurfsmuster, auf die man sich bei der Problemstellung beziehen kann?
Ich habe bereits mehrfach auf die Komplexität des ML-Lebenszyklus hingewiesen und werde dies noch einmal tun, wenn es um die ML-Entwurfsmuster geht. Normalerweise denken ML-Praktiker, dass es keine ML-Entwurfsmuster für das Problem-Framing gibt, weil es einfach keine Entwicklung oder Technik gibt. Es gibt jedoch einige technische Arbeiten, wie z. B. Forschung und Analyse, zu erledigen. Diese Art von technischer Arbeit ist mehr als ausreichend, um ähnliche Erfahrungen in Entwurfsmuster zu klassifizieren, deren Eigenschaften während der Phase gut genutzt werden können. Diese Entwurfsmuster sind hauptsächlich an den ML-Typenbestimmungsprozess gebunden, aber nicht unbedingt. Die folgenden zwei Beispiele sind von den Design Patterns nach Google-Standards inspiriert.
Kehren wir zurück zum Beispiel mit der Lösung für die automatische Auswahl von Schlüsselinformationen. Im Abschnitt über die ML-Typenbestimmung wird erläutert, wie es für diesen Anwendungsfall möglich ist, die Lösung als Regression statt als binäre Klassifikation darzustellen. Diese "Konvertierung" der Ausgabedarstellung wird als Reframing bezeichnet - eines der gängigsten Entwurfsmuster für das Problemframing.
Ein weiteres häufig verwendetes Entwurfsmuster in dieser Phase ist Multilabel, manchmal auch als Multitasking oder Multiklassenklassifikation bezeichnet, aber nur, wenn es sich um den ML-Typ Klassifikation handelt. Das zuvor gezeigte Beispiel von Intertec.ios einzigartiger Erfahrung mit der automatisierten Inhaltserstellung ist ein untraditionelles Multilabel-Entwurfsmuster, bei dem die generierte Ausgabe eines Text2Text-Transformationsmodells als mehrere Labels für den Hauptinhalt und den zusammengefassten Inhalt durch Einfügen von Begrenzern dargestellt wird.
Schlussfolgerung
Abschließend ist zu sagen, dass das Team in dieser Phase unabhängig vom Ergebnis versuchen sollte, seine Bemühungen zu monetarisieren. Selbst bei negativem Ausgang sollte zumindest die valide Analyse in Verbindung mit einem detaillierten Bericht über die durchgeführten Problemframing-Prozesse dem Auftraggeber ein klareres Bild von den erforderlichen Anstrengungen vermitteln, die für die Durchführung eines hochprofessionellen Framings erforderlich sind.
Nach der Lektüre aller Fälle, die ich in diesem recht umfangreichen Leitfaden behandelt habe, wird die Unfähigkeit, mit dem ML-Lebenszyklus fortzufahren, hoffentlich so früh wie möglich erkannt. Wenn nicht, sollte das Team zur anspruchsvolleren Phase der Datenvorbereitung übergehen, in der das Risiko eines Fehlschlags geringer ist.
Letztendlich bringt jedes Problem seine eigenen Besonderheiten mit sich, und wahrscheinlich wird es einige Anwendungsfälle geben, die nicht in das Muster passen, das Sie bereits gelesen haben, was wiederum zu neuen Lösungsstrategien, neuen Entwurfsmustern und neuen Problemfindungsprozessen im ML-Lebenszyklus führen kann.