Kürzlich kündigte Google einen völlig neuen Dienst als Teil seines Google Cloud-Angebots an, der Batch heißt.
Was ist GCP Batch?
Aus den Google-Dokumenten: "...Mit Batch können Sie Aufträge erstellen und ausführen, die auf einem Skript basieren, indem Sie die für die Ausführung der Aufgaben erforderlichen Ressourcen nutzen." Der Dienst ist perfekt für umfangreiche Aufgaben geeignet, da er bis zu 224 CPUs und 896 GB Speicher bietet.
Motivation für die Verwendung von Batch
Google Cloud bietet eine Reihe von Diensten, die Ihnen die Serververwaltung abnehmen und alles für Sie erledigen. Diese Arten von Diensten werden mit dem Etikett "serverlos" angeboten und umfassen unter anderem Cloud Functions.
Cloud Functions sind der perfekte Kandidat für ereignisgesteuerte Architekturen. Nehmen wir folgendes Beispiel: Sie laden eine Datei in den "unverarbeiteten" Speicher-Bucket hoch - dies sendet eine Benachrichtigung an ein von Ihnen konfiguriertes Pub/Sub-Thema, das dann die Cloud-Funktion auslöst. Die Cloud Function verarbeitet dann die hochgeladene Datei und lädt sie in den "verarbeiteten" Speicherbereich hoch. Dieser Grad an Einfachheit in Kombination mit der 1-stündigen Zeitüberschreitung, 32 GB Speicher und 8 CPUs, die die Cloud Function der zweiten Generation bietet, macht sie zur ersten Wahl, wenn es um Szenarien wie dieses geht.
Monate vergehen, und die Dateien werden problemlos hochgeladen und verarbeitet, dann erhalten Sie plötzlich eine Meldung, dass die Cloud-Funktion fehlgeschlagen ist. Plötzlich ist die "Flitterwochen"-Phase der Nutzung des neuen Dienstes vorbei. Sie beginnen mit der Fehlersuche und stellen fest, dass die hochgeladene Datei mehrere GB groß ist und mehrere Millionen Einträge enthält. Die Größe der Datei in Verbindung mit der komplexen Verarbeitung durch die Cloud-Funktion führt dazu, dass die Cloud-Funktion die 1-Stunden-Zeitüberschreitung erreicht.
Glücklicherweise hat der neue Batch-Dienst keine Zeitüberschreitung, d. h. er führt Ihr Skript so lange aus, bis er ein Ergebnis liefert. Batch akzeptiert zwei Arten von Bereitstellungen: ein Bash-Skript oder ein Docker-Image. Wir müssen unsere Python-Cloud-Funktion innerhalb von Batch migrieren, daher benötigen wir ein Docker-Image, das unseren Python-Code enthält.
Erstellen des Docker-Abbilds
Beginnen wir mit der Erstellung eines "Batch"-Ordners, der unseren Code und die Dockerdatei enthalten wird. Navigieren Sie zu diesem Ordner und erstellen Sie eine virtuelle Python-Umgebung:
python3 -m venv env
und aktivieren Sie dann die virtuelle Umgebung:
source env/bin/activate
Jetzt können wir mit der Arbeit an unserem Code beginnen. Der Einfachheit halber werden wir das einfachste Beispiel eines Python-Skripts erstellen - wir werden "Hello from Batch" drucken. Unsere main.py wird also wie folgt aussehen:
print("Hallo von Batch")
Wir müssen dem Docker-Image mitteilen, welche Anforderungen es benötigt, um das Skript main.py auszuführen. Daher erstellen wir eine Anforderungsdatei, indem wir Folgendes ausführen:
pip freeze > requirements.txt
Schließlich können wir das Dockerfile schreiben:
FROM python:3.8 WORKDIR /script COPY requirements.txt . RUN pip install -r requirements.txt COPY main.py . ENTRYPOINT \[ "python3", "main.py"\]
Wie Sie sehen können, handelt es sich um eine wirklich einfache Dockerdatei, die das Python3.8-Image bezieht, die erforderlichen Anforderungen für das Skript installiert und schließlich das Skript ausführt. Dies ist die Struktur unseres kleinen Projekts:
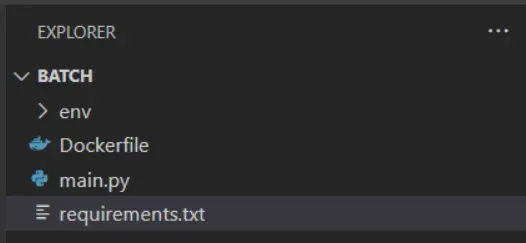
Wir sind nun bereit, das Docker-Image zu erstellen. Unser Ziel ist es, das erstellte Docker-Image in die GCP Artifact Registry hochzuladen, da wir es von dort aus leicht für unseren Batch-Job verwenden können. Wenn Sie es noch nicht getan haben, erstellen Sie ein Repository zum Speichern der Docker-Images. Wir werden es "batch-tutorial" nennen.
Um das Image in Artifact Registry veröffentlichen zu können, muss das Image in einem bestimmten Format getaggt werden, das GCP erwartet:
LOCATION-docker.pkg.dev/PROJECT/REPOSITORY/IMAGE:TAG
wobei
- LOCATION ist der regionale oder multiregionale Standort des Repositorys.
- PROJECT ist Ihre Google Cloud-Projekt-ID.
- REPOSITORY ist der Name des Repositorys, in dem das Bild gespeichert ist.
- IMAGE ist der Name des Bildes im Repository.
- TAG ist das Tag für die Version, die Sie löschen möchten.
Wir erstellen also unser Docker-Image, indem wir Folgendes ausführen:
docker build -t europe-west3-docker.pkg.dev/PROJECT/batch-tutorial/batch:tutorial .
Veröffentlichen des Docker-Abbilds
Nachdem wir das Docker-Image mit dem spezifischen Tag erfolgreich erstellt haben, können wir das Docker-Image nun in der Artifact Registry veröffentlichen. Bitte stellen Sie sicher, dass Sie bei GCP und bei der Docker-Registry authentifiziert sind, bevor Sie versuchen, das Image zu veröffentlichen, was durch Ausführen von
docker push europe-west3-docker.pkg.dev/PROJECT/batch-tutorial/batch:tutorial
Nach der Veröffentlichung des Docker-Images ist alles bereit, um unseren Batch-Job zu erstellen, also machen wir das.
Batch-Job erstellen
Das letzte Teil des Puzzles ist die Erstellung des Batch-Jobs. Navigieren Sie zu Google Cloud und klicken Sie oben auf dem Bildschirm auf Erstellen. Daraufhin wird ein neues Fenster zum Erstellen des Batch-Auftrags geöffnet. Beachten Sie, dass Sie nur eine begrenzte Anzahl von Regionen auswählen können, da sich der Batch-Dienst noch im Vorschaumodus befindet. Für die URL des Container-Images fügen Sie die URL des Docker-Images ein, das Sie im vorherigen Schritt gepusht haben, und unten wählen Sie, wie viele Ressourcen Sie für den Batch-Job zuweisen möchten, und klicken Sie auf Erstellen. GCP muss nun die von Ihnen angeforderten Ressourcen zuweisen, sodass der Auftrag zunächst den Status "in der Warteschlange" hat. Sobald die Ressourcen zugewiesen sind, ändert sich der Status in "geplant". Schließlich beginnt der Batch-Job mit der Ausführung des Python-Skripts und der Status ändert sich in "running".
Sobald der Batch-Job erfolgreich war (oder fehlgeschlagen ist), können wir ihn in der Detailansicht öffnen und auf "Cloud Logging" klicken. In unserem Fall können wir sehen, dass der Batch-Job "Hello from Batch" gedruckt hat. Hurra!
Okay, das klingt alles gut für ein einfaches "Hello World"-Beispiel, aber wir haben über Batch-Jobs als Alternativen zu ereignisgesteuerten Cloud-Funktionen gesprochen. Wir können ereignisgesteuerte Batch-Jobs nicht so einfach erstellen wie die Cloud-Funktionen - stattdessen müssen wir GCP-Workflows verwenden.
Ereignisgesteuerter Batch-Job mit GCP-Workflows
Stellen wir uns erneut ein Szenario vor: Sie laden Dateien in Ihren "unverarbeiteten" Speicher-Bucket hoch und die Datei wird verarbeitet und gespeichert. Der Unterschied zum vorherigen Szenario ist, dass die Datei nun mit einem Batch-Job verarbeitet wird.
Um eine Datei aus dem GCP-Speicher herunterzuladen, müssen wir zunächst das erforderliche Paket installieren:
pip install google-cloud-storage
Nun schreiben wir den Python-Code:
from google.cloud import storage from loguru import logger as log import os def download\_file(bucket\_name, source\_blob\_name, destination\_file\_name):
\# Die ID des GCS-Eimers bucket\_name = os.environ.get("BUCKET") \# Die ID des GCS-Objekts source\_blob\_name = os.environ.get("FILE") \# Der Pfad, in den die Datei heruntergeladen werden soll destination\_file\_name = "batch-tutorial.txt" storage\_client = storage.Client() bucket = storage\_client.bucket(bucket\_name) blob = bucket.blob(source\_blob\_name) blob.download\_to\_filename(destination\_file\_name) log.info(f "Heruntergeladenes Speicherobjekt '{Quelle\_blob\_name}' aus dem Bucket '{Bucket\_name}' in die lokale Datei '{Ziel\_file\_name}'") if \_name\_name== "\_haupt\_name": download\_file(bucket\_name\="", Quelle\_blob\_name\="", Ziel\_file\_name\="")
Sie werden feststellen, dass wir zwei Umgebungsvariablen verwenden - Bucket-Name und Quelldatei. Diese sind noch nirgends definiert, aber wir werden sie in den nächsten Schritten innerhalb des Workflows definieren.
Starten wir nun:
pip freeze > requirements.txt
damit unsere Anforderungen auf dem neuesten Stand sind.
Der Inhalt der Dockerdatei ist genau derselbe wie bei unserem vorherigen Beispiel "Hello from Batch".
Jetzt erstellen und pushen wir das Docker-Image. Wir verwenden die gleichen Befehle wie zuvor und ändern nur das Image-Tag:
docker build -t europe-west3-docker.pkg.dev/PROJECT/batch-tutorial/batch:event-driven-tutorial . docker push europe-west3-docker.pkg.dev/PROJECT/batch-tutorial/batch:event-driven-tutorial
Nachdem das Docker-Image in die Artifact Registry übertragen wurde, können wir mit der Arbeit am Workflow beginnen. Der Workflow wird bei jedem Upload in den 'unprocessed' Bucket ausgelöst und erhält ein Ereignis vom Bucket, das ihm mitteilt, welche Datei hochgeladen wurde.
Das Wichtigste zuerst: Gehen Sie zu GCP Workflows und klicken Sie auf Erstellen. Es öffnet sich ein neuer Bildschirm, in dem wir einen Namen für den Workflow festlegen, eine Region und ein Dienstkonto auswählen und optional einen Auslöser konfigurieren müssen. Vergewissern Sie sich, dass das von Ihnen gewählte Dienstkonto über ausreichende Berechtigungen für den Aufruf der Batch-API verfügt.
Da wir den Workflow bei jedem "Datei-Upload" in einen Bucket ausführen wollen, klicken wir auf Add new trigger und wählen Eventarc. Hier entscheiden wir uns für Cloud Storage als Event Provider, suchen und wählen unseren "unprocessed" Bucket und wählen google.cloud.storage.object.v1.finalized als Trigger-Ereignis.
Wir sind nun bereit, den Workflow zu definieren, der wie folgt aussehen wird:
main: params: [event] steps: - init: assign: - projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} - region: "europe-north1" - batchApi: "batch.googleapis.com/v1" - batchApiUrl: ${"https://" + batchApi + "/projects/" + projectId + "/locations/" + region + "/jobs"} - imageUri: "europe-west3-docker.pkg.dev/PROJECT/batch-tutorial/batch:event-driven-tutorial" - jobId: ${"job-" + string(int(sys.now()))} - log_event: call: sys.log args: text: ${event} severity: INFO - extract_bucket_and_file: assign: - bucket: ${event.data.bucket} - file: ${event.data.name} - logCreateBatchJob call: sys.log args: data: ${"Creating and running the batch job " + jobId} - createAndRunBatchJob: call: http.post args: url: ${batchApiUrl} query: job_id: ${jobId} headers: Content-Type: application/json auth: type: OAuth2 body: taskGroups: taskSpec: computeResource: cpuMilli: 4000 memoryMib: 32000 runnables: - container: imageUri: ${imageUri} environment: variables: BUCKET: ${bucket} FILE: ${file} taskCount: 1 Parallelität: 1 logsPolicy: Ziel: CLOUD_LOGGING ergebnis: createAndRunBatchJobResponse
Zu Beginn der Workflow-Definition setzen wir das params-Schlüsselwort, um das vom Workflow-Auslöser gesendete Ereignis (den Datei-Upload) zu empfangen, das wir verwenden werden, um den Bucket und den Dateinamen zu erhalten (die wir als Umgebungsvariablen in unserer main.py-Datei verwenden).
Als Nächstes erhalten wir in unserem Init-Schritt die GCP-Projekt-ID, wir legen die Region fest, in die der Batch-Job zusammen mit der Batch-API bereitgestellt wird, die Batch-API-URL, die URI des Docker-Images, das wir erstellen und in die Artifact Registry pushen, und die Batch-Job-ID.
Im Schritt extract_bucket_and_file extrahieren wir aus dem empfangenen Ereignis den Bucket-Namen und den Dateinamen. Damit sind wir bereit, den Batch-Job zu definieren.
Wir beginnen die Definition des Batch-Jobs, indem wir eine POST-Anfrage an die Batch-API-URL senden, die wir im Schritt init definiert haben. Als Nächstes werden die Rechenressourcen für den Auftrag definiert - in unserem Fall fordern wir 4 CPUs und 32 GB Speicher an. Schließlich müssen wir dem Batch-Job mitteilen, welcher Container ausgeführt werden soll, indem wir die imageUri angeben, die wir im init-Schritt definiert haben. Wir setzen den Bucket und den Dateinamen, den wir aus dem Ereignis extrahiert haben, als Umgebungsvariablen für das Image, die wir dann in der Datei main.py verwenden. Damit ist der Arbeitsablauf fertig.
Schließlich kommen wir zu einem Stadium, in dem wir die Implementierung testen können. Wenn alles wie erwartet funktioniert, sollten wir eine Datei in den "unprocessed"-Bucket hochladen, die dann den Workflow ausführt, und der Workflow erstellt dann einen neuen Batch-Job. Der Batch-Job sollte die hochgeladene Datei herunterladen.
Navigieren Sie zu Ihrem "unprocessed" Bucket auf GCP und laden Sie eine Datei Ihrer Wahl hoch. Gehen Sie dann zum Workflow-Dashboard und überprüfen Sie, ob der Workflow ausgeführt wurde. Wenn Sie alles richtig gemacht haben, sollte er den Status Erfolg haben.
Der nächste Schritt ist die Navigation zu unserem Batch Job Dashboard. Hier können wir sehen, dass unser Batch-Job erstellt wurde. Nach einigen Minuten beginnt der Batch-Job zu laufen und wird ziemlich schnell in den Status "erfolgreich" übergehen (da unser Python-Skript sehr einfach ist).
Jetzt können wir die Protokolle für den Batch-Job öffnen und sehen, dass der Batch-Job die Datei heruntergeladen hat, die wir in den "unverarbeiteten" Speicherbereich hochgeladen haben. Großartig!
Und was noch toller ist: Wir haben derzeit mehrere offene Stellen bei Intertec.io. Wenn Sie Teil einer Umgebung sein wollen, die Sie inspiriert, zu lernen, zu wachsen und mit gutem Beispiel voranzugehen, dann sollten Sie sich unbedingt bei uns melden!