Aufbau von RAG-basierten Anwendungen für die Produktion
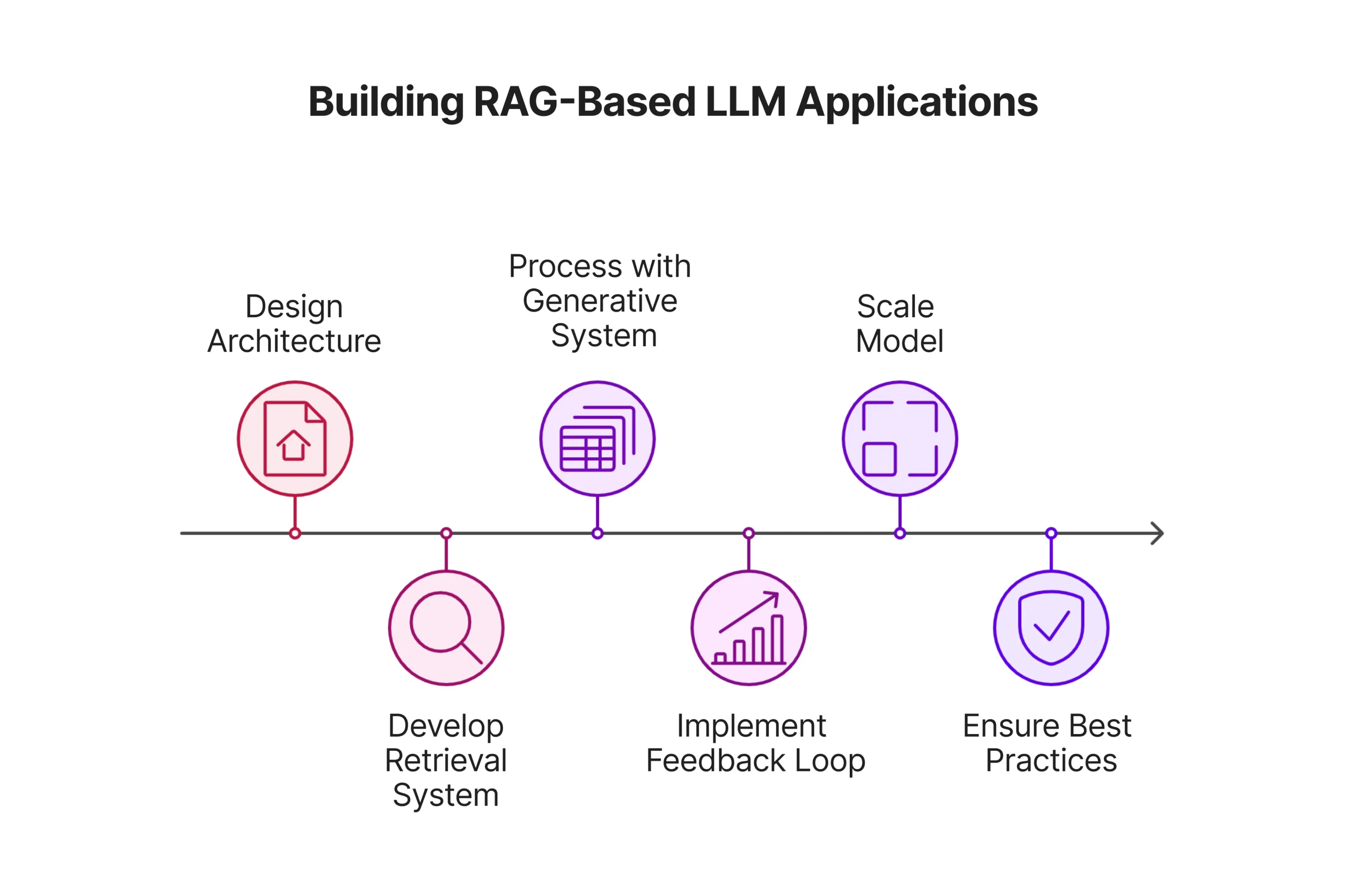
Es ist zu beobachten, dass die RAG-basierte Anwendung für ein breites Spektrum von Aufgaben entsprechend den spezifischen Bedürfnissen fein abgestimmt werden kann. Um RAG-basierte Sprachmodell (LLM)-Anwendungen für die Produktion von Grund auf zu konstruieren, sind langwierige Vorsichtsmaßnahmen erforderlich. Zuallererst sollte die Architektur behutsam entworfen werden. Dies geschieht, indem das System in verschiedene Teile zerlegt wird, die letztendlich kohärent interagieren können. Solche Komponenten sind die Abrufschicht, die generative Schicht, die Rückkopplungsschleife und die externe Wissensbasis. Jede dieser Schlüsselkomponenten spielt individuelle Rollen, die nahtlos ineinander übergehen. Daher ist es von entscheidender Bedeutung, jede Ebene zu untersuchen, um ihre Funktion und ihren Zweck zu verstehen. Dies führt zur zweiten Phase des Aufbaus von RAG-basierten LLM-Anwendungen für die Produktion, nämlich dem Entwicklungsworkflow. Nach der Eingabe eines Benutzers sammelt das Retrievalsystem zunächst relevante Informationen aus externen Quellen wie Datenbanken oder Suchmaschinen, die dann an das generative System wie GPT weitergeleitet werden, das das Wissen zu einer verständlichen Antwort als Ausgabe verarbeitet. Die Rückkopplungsschleife hat die Aufgabe, die Genauigkeit des Systems auf der Grundlage des Interaktionsverhaltens und der Rückmeldungen des Benutzers kontinuierlich zu verbessern, während die externe Wissensbasis als Informationsquelle für den Retrievalschritt dient. Im letzten Schritt der Entwicklung von RAG-basierten LLM-Anwendungen für die Produktion sollten die Entwickler das Modell entsprechend ihrer Bedürfnisse skalieren. Einige der besten Praktiken für die Erstellung effizienter RAG-Anwendungen sind eine angemessene Indizierung mittels Vektorsuche oder FAISS sowie Datenvektorisierungstechniken. Dadurch können die Anwendungen skaliert werden, um sowohl große Datenbanken als auch einen hohen Benutzerverkehr zu verwalten. Es sollte beachtet werden, dass es auch die beste Praxis ist, konsistente Zyklen der Überwachung und des Feedbacks zu haben, um Leistungsengpässe zu untersuchen. Eine weitere wichtige Praxis, die eingehalten werden muss, ist die Gewährleistung von Datensicherheit und Datenschutzmaßnahmen sowie die Einhaltung der Allgemeinen Datenschutzverordnung (GDPR) und anderer bereits bestehender Vorschriften.
Wie man mit der RAG-Anwendung anfängt
Nachdem die Vorsichtsmaßnahmen getroffen wurden, erfordern die Schritte zur Erstellung einer RAG-Anwendung Aufmerksamkeit bis ins Detail, insbesondere wenn es sich um den ersten Versuch handelt. Obwohl es Tutorials gibt, die als Anleitung für die Erstellung von RAG-basierten Anwendungen dienen, sollten Entwickler zunächst das Ziel der RAG-basierten Anwendung bestimmen, das von der Generierung von Inhalten bis zu personalisierten Assistenten reicht. Während des Entwicklungsprozesses sollte der Retrieval- und Generierungsansatz mit Sorgfalt ausgewählt werden. Dabei kann es sich um traditionelle Ansätze wie TF-IDF für die Retrieval-Komponente und ein GPT-3/4 für die generative Komponente handeln. Diese Ansätze müssen dann in die Retrieval- bzw. die generative Komponente eingebaut werden, wobei jedes Modell dafür sorgen muss, dass sie auf effiziente und optimierte Weise funktionieren. Beispielsweise sollte für das Retrieval-Modell eine Vorverarbeitung der Dokumente durchgeführt werden, indem die Dokumente von irrelevanten Informationen für das Retrieval bereinigt werden, während für die generative Komponente den Entwicklern empfohlen wird, das Modell auf domänenspezifische Daten abzustimmen, um die Erzeugung von Antworten mit inhaltlichen Nischenparametern zu verbessern. Nicht zuletzt sollen die Komponenten für eine nahtlose Integration miteinander verbunden werden. Es versteht sich von selbst, dass die Entwickler zusätzliche Anstrengungen unternehmen sollten, um den Abruf-erweiterten Generierungsprozess der Anwendung zu überwachen, um sicherzustellen, dass seine Leistung den erwarteten Standards entspricht. Dazu können verfügbare Tools wie Kubernetes verwendet werden, um die Bereitstellung der RAG-basierten Anwendung in einer Cloud-Umgebung zu orchestrieren, oder sogar Streamlit, um die Anwendung vor der Implementierung zu prototypisieren.
Fortgeschrittene Konzepte: Bewerten und Verbessern von RAG-Anwendungen
Nach dem Aufbau einer funktionierenden RAG-basierten Anwendung ist es unerlässlich, Bewertungen hinsichtlich ihrer Leistung und Effizienz durchzuführen. Die Funktionsweise einer RAG-basierten Anwendung kann anhand verschiedener Bewertungsmetriken wie der Abrufleistung gemessen werden. Diese Methode konzentriert sich auf die Wiederauffindbarkeit und die Genauigkeit des Retrievalmodells innerhalb der RAG-basierten Anwendung, um die Antworteffizienz des Systems zu bewerten. Sie bewertet die Zeit, die die Anwendung benötigt, um relevante Informationen abzurufen, sowie die Genauigkeit und Vielfalt der abgerufenen Inhalte. Diese Überlegungen werden berücksichtigt, da das System die Aufgabe hat, präzise und geprüfte Daten aus umfangreichen Datenbanken abzurufen, um den Abfrageanforderungen der Benutzer gerecht zu werden. Neben der Bewertung des Retrievalmodells kann auch das Generierungsmodell bewertet werden, indem die generative Genauigkeit und die Komplexität untersucht werden. Für RAG-basierte LLM-Anwendungen gibt es die Recall-Oriented Understudy for Gisting Evaluation (ROUGE) als hilfreiches Werkzeug für den Vergleich von n-Gramm-Überschneidungen zwischen den referenzierten Texten und der generierten Ausgabe. Ein weiteres Beispiel für eine Bewertungsmetrik wäre die menschliche Bewertung. Dieser Bewertungsprozess wird von einer Person durchgeführt, die bewertet, wie natürlich und kohärent die von der Anwendung generierten Antworten sind. Diese Metrik misst die Flüssigkeit und Informativität der RAG-basierten Anwendung, so dass sie in der Lage ist, ein abgerundetes Benutzererlebnis als Ganzes zu bieten. Die Messung der Effizienz der erstellten RAG-basierten Anwendung ist wichtig, um ihre Fähigkeiten und Grenzen zu verstehen und Raum für konsequente Verbesserungen innerhalb des Systems zu schaffen.
Die Verbesserung der RAG-basierten Anwendung kann durch die Optimierung der Retrieval-Komponente sowie der generativen Komponente erfolgen. Erstere wird in der Regel durch die Verwendung besser abgestimmter Einbettungsmodelle wie BERT für präzisere linguistische Ähnlichkeiten oder sogar durch die Erweiterung der Datenabdeckung und -vielfalt durch die Integration eines größeren Parameters an externem Wissen verbessert. Andererseits kann das letztgenannte Modell verbessert werden, indem die Möglichkeit von Halluzinationen durch Mechanismen zur Faktenüberprüfung verringert wird, um sicherzustellen, dass die generierten Antworten auf bereits vorhandenem Wissen aus den abgerufenen Daten beruhen. Darüber hinaus haben die Entwickler die Möglichkeit, die Zusammenarbeit zwischen dem Abfrage- und dem generativen Modell zu verbessern, indem sie den Abfrage- und den erweiterten Generierungsprozess gemeinsam verfeinern, um eine nahtlosere Interaktion zu erreichen. Es können auch Feedback-Schleifen eingerichtet werden, indem die generative Komponente die Abfragekomponente bei der Suche nach zuverlässigeren Datenquellen beeinflusst.
Transformative Anwendungen für verschiedene Branchen
Angesichts der enormen Vorteile, die mit RAG-basierten Anwendungen einhergehen, haben globale Sektoren bereits damit begonnen, das System in ihren Bereichen zu implementieren, um seine Wettbewerbsvorteile zu optimieren. So ist beispielsweise im Gesundheitswesen ein Aufwärtstrend bei der Nutzung von RAG-basierten Anwendungen zur Unterstützung der Patientenversorgung zu verzeichnen. Es ermöglicht den Gesundheitsdienstleistern, medizinische Informationen in Echtzeit abzurufen, egal ob es sich um allgemeine oder um Nischeninformationen handelt, und diese informativen Daten zu nutzen, um die richtigen Entscheidungen in Bezug auf Diagnose und Behandlung zu treffen. Auch im Bildungsbereich werden RAG-basierte Anwendungen als Lernwerkzeuge eingesetzt, um die Lernerfahrung zu verbessern. Die Anwendungen werden nun zu Tutorensystemen für die Echtzeitunterstützung bei Anfragen von Schülern und Lehrern sowie für die dynamische Generierung von Inhalten für forschungsbasierte Zusammenfassungen oder Erklärungen weiterentwickelt. Die Effizienz der Abfragekomponente der RAG-basierten Anwendung ermöglicht es den Nutzern, die Zeit zu sparen, die für die Recherche in primären und sekundären Informationsquellen benötigt wird. Darüber hinaus kommt die Architektur der RAG-Anwendung auch der Finanzindustrie bei der Bewertung von Risiken und der Aufdeckung potenzieller Betrugsfälle im Alltag zugute. Damit steht den Anwendern in der Finanzbranche ein Echtzeit-Recherchesystem zur Verfügung, das ihnen hilft, informierte und gewichtige Entscheidungen zu treffen. Ausgehend davon, wie die Mechanismen der RAG-basierten Anwendungen von den Branchen täglich optimiert werden, lässt sich feststellen, dass die Architektur flexibel funktioniert und in vielen Bereichen anpassbar ist. Der Einzelhandel zum Beispiel kann das System auch nutzen, um Einblicke in den Warenbestand zu erhalten, um ihn besser verwalten zu können, und sich auf die Technologie verlassen, um bei Bedarf personalisierte industrielle Empfehlungen zu geben.