Warum Vektorspeicher in modernen KI-Systemen wichtig sind
Wir erleben derzeit einen grundlegenden Wandel in der Art und Weise, wie Maschinen Daten verstehen. Jahrzehntelang bestand die Suche und der Abruf von Daten aus dem Abgleich von Schlüsselwörtern - finde die exakte Zeichenfolge, gib die exakte Zeile zurück. Dieses Modell funktionierte gut für strukturierte, vorhersehbare Daten. Große Sprachmodelle (LLMs) haben jedoch alles verändert. Sie denken nicht in Schlüsselwörtern. Sie denken in Bedeutungen.
Genau aus diesem Grund haben sich Vektorspeicher von einem Nischenthema der Datentechnik zu einem unverzichtbaren Bestandteil der modernen KI-Infrastruktur entwickelt. Sie sind die Brücke zwischen dem, was die Nutzer fragen, und dem, was KI-Systeme sinnvoll abrufen können. Ohne sie wird selbst das ausgefeilteste LLM vergesslich und allgemein. Mit ihnen kann die KI Ihre geschützten Daten im Produktionsmaßstab durchdenken.
Die Zahlen untermauern dies. Laut MarketsandMarkets wird der globale Markt für Vektordatenbanken von ** 2,65 Mrd. US-Dollar im Jahr 2025 auf 8,95 Mrd. US-Dollar im Jahr 2030 anwachsen - eine**CAGR von 27,5 %. Der Bericht "State of AI" von Databricks hat ergeben, dass Vektordatenbanken, die RAG-Anwendungen unterstützen, **im Jahresvergleich um 377 %**gewachsen sind - dasschnellste Wachstum aller gemessenen LLM-bezogenen Technologiekategorien.
Für CTOs, die heute KI-Systeme aufbauen oder skalieren, sind Vektorspeicher eine Infrastrukturentscheidung. Nicht optional. Nicht experimentell. Kern.
Was ist ein Vektorspeicher?
Definition eines Vektorspeichers
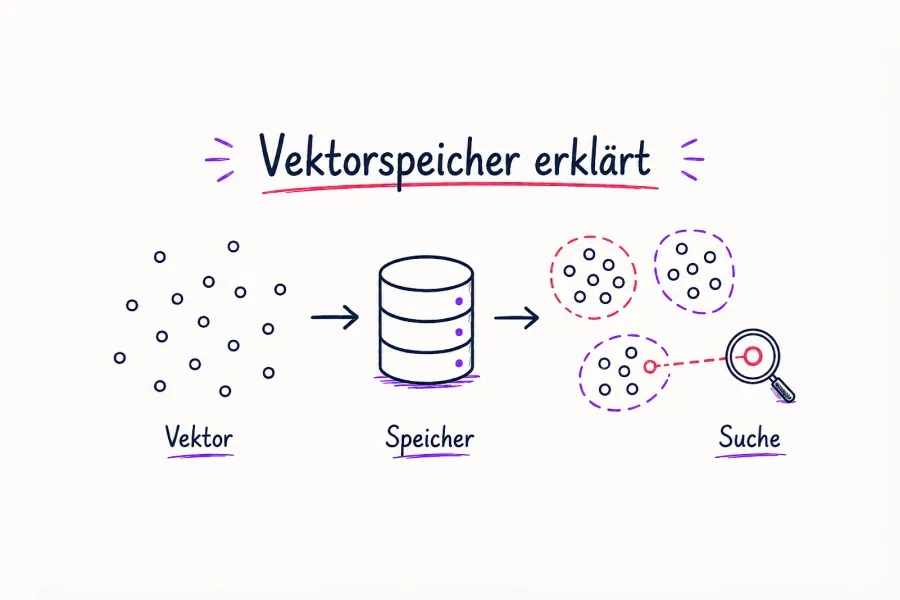
Vereinfacht ausgedrückt ist ein Vektorspeicher ein spezialisiertes Speichersystem, das zum Speichern, Indizieren und Durchsuchen hochdimensionaler numerischer Darstellungen von Daten, so genannter "Einbettungen", konzipiert ist. Vektorspeicher werden zwar häufig mit künstlicher Intelligenz in Verbindung gebracht, können aber auch für jede andere Anwendung verwendet werden, die eine ähnlichkeitsbasierte Suche über numerische Repräsentationen erfordert. Wenn Sie einen Text, ein Bild, einen Ton oder ein Dokument in ein Einbettungsmodell einspeisen (wie OpenAIs text-embedding-3-small, text-embedding-3-large oder ein Sentence Transformers-Modell), wandelt das Modell den Text in eine Liste von Hunderten oder Tausenden von Gleitkommazahlen um. Diese Liste ist ein Vektor, der die semantische Bedeutung der ursprünglichen Daten wiedergibt.
So ergeben beispielsweise die Sätze "Ich liebe meinen Hund" und "Mein Welpe macht mich glücklich" sehr ähnliche Vektoren, da sie eine ähnliche Bedeutung haben. Eine herkömmliche Datenbank würde zwei völlig unterschiedliche Zeichenketten sehen, die sich nicht überschneiden. Ein Vektorspeicher sieht sie als Nachbarn im hochdimensionalen Raum.
Dies ist die wichtigste Erkenntnis: Vektorspeicher ermöglichen die Ähnlichkeitssuche, nicht die Suche nach exakten Übereinstimmungen. Dieser Unterschied ist bei KI-Anwendungen von enormer Bedeutung.
Wie funktioniert eine Vektordatenbank?
Wenn Daten in einen Vektorspeicher gelangen, folgen sie einer bestimmten Pipeline. Es ist erwähnenswert, dass eine Vektordatenbank einen Schritt über einen einfachen Vektorspeicher hinausgeht, indem sie zusätzlich zu den grundlegenden Speicher- und Abfragefunktionen umfassende Datenbankfunktionen wie CRUD-Operationen, Indizierungsoptimierung und Abfrageverwaltung bietet. So funktioniert es:
Erzeugung von Einbettungen - Rohdaten (Text, Bild oder Audio) werden in ein Einbettungsmodell eingespeist. Das Modell gibt einen numerischen Vektor mit fester Länge aus, z. B. 3072 Dimensionen für das OpenAI-Modell "Text-Embedding-3-large".
Indizierung - Der Vektor wird zusammen mit den Metadaten gespeichert und für einen schnellen Abruf indiziert. Die meisten Vektorspeicher verwenden ANN-Algorithmen (Approximate Nearest Neighbor), um dies effizient und in großem Maßstab durchzuführen. HNSW (Hierarchical Navigable Small World graphs) ist eine der am weitesten verbreiteten Indexierungsstrategien.
Ähnlichkeitssuche - Zum Zeitpunkt der Abfrage werden die Eingaben des Benutzers ebenfalls in einen Vektor umgewandelt. Die Datenbank sucht dann anhand von Ähnlichkeitsmetriken wie den folgenden nach Vektoren, die dem Abfragevektor ähnlich sind:
- Cosinus-Ähnlichkeit - Misst den Winkel zwischen zwei Vektoren. Ideal für Texteinbettungen.
- Euklidischer Abstand - Misst den geradlinigen Abstand im Vektorraum.
- Punktprodukt - Schnell, wird oft verwendet, wenn Vektoren normalisiert sind.
Rangfolge der Ergebnisse - Die Datenbank gibt die am besten übereinstimmenden Vektoren (und den zugehörigen Inhalt) zurück, geordnet nach dem Ähnlichkeitswert.
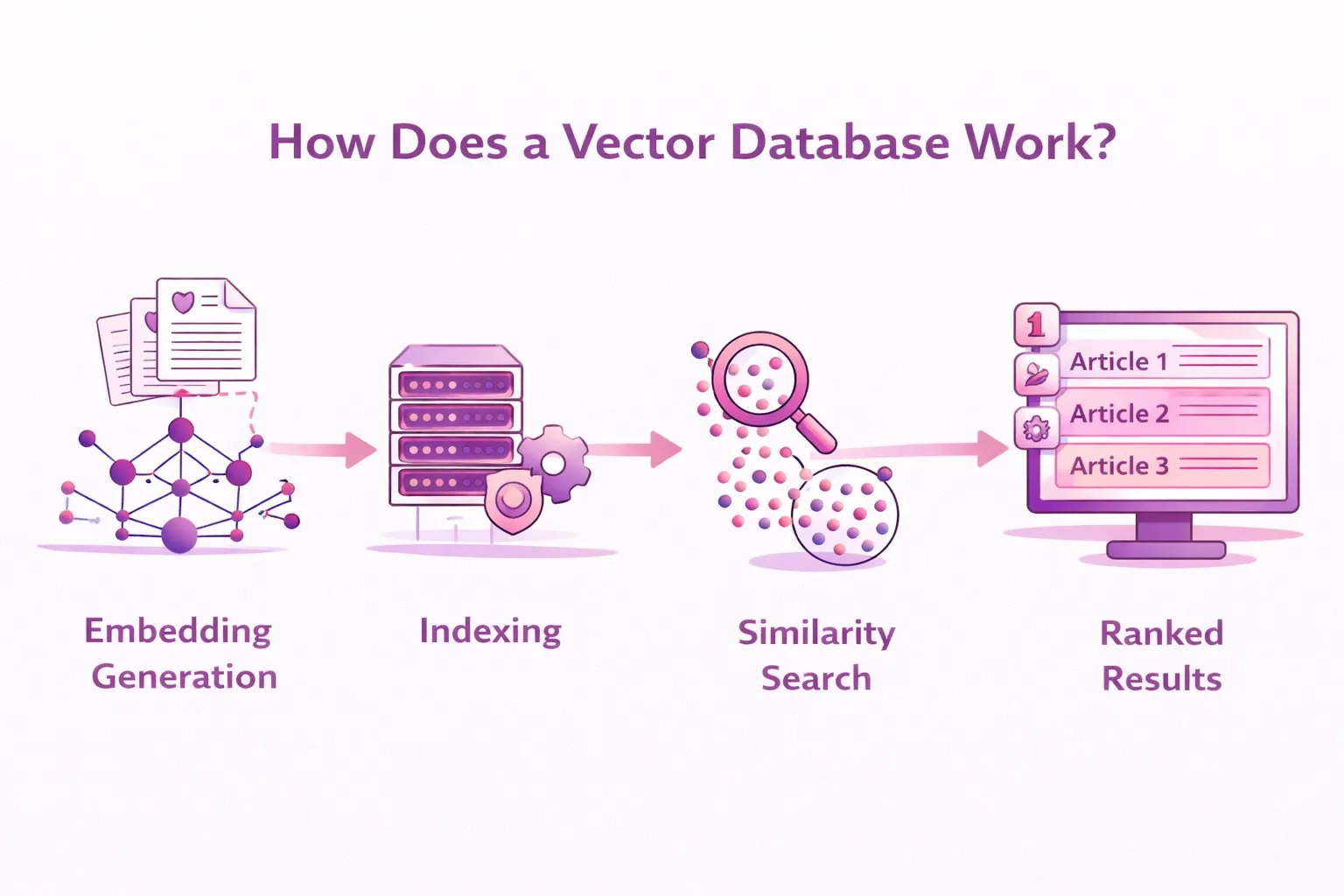
Der gesamte Ablauf, von der Benutzerabfrage bis zu den geordneten semantischen Ergebnissen, dauert in der Regel nur wenige Millisekunden, was Vektorspeicher für KI-Systeme in der Produktion interessant macht.
Vektordatenbank vs. traditionelle Datenbank
Strukturelle Hauptunterschiede
Um zu verstehen, warum es Vektorspeicher gibt, müssen wir wissen, wofür herkömmliche Datenbanken nicht ausgelegt sind.
| Merkmal | Traditionelle Datenbank | Vektordatenbank |
| Datenmodell | Strukturierte Zeilen/Spalten | Hochdimensionale Embeddings |
| Abfragetyp | Exakte Übereinstimmung (SQL) | Ähnlichkeitssuche (ANN) |
| Schema | Starr, vordefiniert | Flexibel, metadatenbasiert |
| Ideale Workloads | OLTP, transaktionale Systeme | Semantische KI, Retrieval |
| Skalierungsachse | Vertikal (häufig) | Horizontal (verteilt) |
Herkömmliche Datenbanken beantworten Fragen wie "Gib mir alle Nutzer, bei denen Alter > 30 und Stadt = 'Berlin'." Das ist deterministisch. Vektordatenbanken beantworten Fragen wie "Welche Dokumente sind dieser Anfrage semantisch am ähnlichsten?". Das ist probabilistisch. Beide sind gültig. Sie lösen jedoch grundlegend unterschiedliche Probleme.
Wann sollte man welchen Ansatz verwenden?
Die gute Nachricht ist, dass man sich nicht für das eine oder das andere entscheiden muss. In der Produktion von KI-Systemen verwenden wir fast immer beide Ansätze. Hier ist ein praktischer Weg, darüber nachzudenken:
- Verwenden Sie eine relationale Datenbank oder eine Dokumentendatenbank für die Speicherung strukturierter Geschäftsdaten - Kundendatensätze, Transaktionen und Inventar.
- Verwenden Sie einen Vektorspeicher für das semantische Retrieval, d. h. den Abgleich von Benutzeranfragen mit relevanten Dokumenten, Wissensdatenbankeinträgen oder Produktbeschreibungen.
- Kombinieren Sie diese mithilfe der Metadatenfilterung in Ihrem Vektorspeicher, um die Ergebnisse vor der Anwendung der Ähnlichkeitssuche einzugrenzen.
Die Debatte zwischen Vektordatenbanken und herkömmlichen Datenbanken ist weitgehend eine falsche Dichotomie. In ausgereiften KI-Architekturen ergänzen sie sich gegenseitig.
Arten von Vektordatenbanken
Nicht alle Vektorspeicher sind auf die gleiche Weise aufgebaut. Bei der Evaluierung Ihrer Optionen ist es hilfreich, die drei Hauptkategorien zu verstehen.
1. Native Vektordatenbanken
Diese Tools wurden von Grund auf für KI-Workloads entwickelt. Sie legen den Schwerpunkt auf schnelle Ähnlichkeitssuche, skalierbare Indizierung und enge Integration mit Einbettungsmodellen und KI-Frameworks.
Beispiele hierfür sind Pinecone, Qdrant, Weaviate, Milvus und Chroma. FAISS (Facebook AI Similarity Search) ist nach wie vor einer der leistungsfähigsten und benutzerfreundlichsten Vektorspeicher, der vor allem für die lokale Entwicklung und die Suche mit hohem Durchsatz beliebt ist. Diese Lösungen bieten in der Regel die beste Rohabrufleistung, erweiterte Filteroptionen und Unterstützung für komplexe Indexierungsstrategien wie IVF-Flat und HNSW. Sie erfordern jedoch eine spezielle Infrastruktur und einen betrieblichen Overhead.
2. Hybride Datenbanken mit Vektorfähigkeiten
Dies sind traditionelle Datenbanken, die die Vektorsuche als Funktion hinzugefügt haben. PostgreSQL mit der pgvector-Erweiterung, MongoDB Atlas Vector Search, Redis Stack und die dichte Vektorunterstützung von Elasticsearch fallen alle in diese Kategorie.
Der Kompromiss ist einfach: Sie erhalten eine einfachere Integration in die bestehende Infrastruktur und ein vertrautes Betriebsmodell. Allerdings kann es bei extremer Skalierung zu Leistungseinbußen kommen, da diese Tools nicht speziell für die hochdimensionale Ähnlichkeitssuche entwickelt wurden. Für viele Anwendungsfälle in Unternehmen überwiegt die Einfachheit der Integration das Leistungsdelta.
3. Cloud-verwaltete Vektordienste
Dies sind vollständig verwaltete Vektordatenbankdienste, die von Cloud-Anbietern angeboten werden. Die k-NN-Funktionalität von Amazon OpenSearch, Azure AI Search mit Vektorfunktionen und Googles Vertex AI Vector Search fallen alle in diese Kategorie. Darüber hinaus bietet AWS Amazon Bedrock Knowledge Bases an, einen der fortschrittlichsten und skalierbarsten Ansätze für die semantische Suche in der Produktion. Bedrock wickelt den gesamten RAG-Workflow ab und unterstützt mehrere Vektorspeicher-Backends, darunter OpenSearch Serverless, Aurora PostgreSQL und die kürzlich eingeführten Amazon S3 Vectors, die Kosteneinsparungen von bis zu 90 % für groß angelegte Vektorspeicher bieten.
Die Vorteile liegen auf der Hand: keine zu verwaltende Infrastruktur, integrierte Skalierung und enge Integration mit dem breiteren Cloud-KI-Ökosystem. Zu den Nachteilen gehören eine mögliche Anbieterbindung und höhere Kosten pro Abfrage bei großem Umfang. Für Teams, die der Produktionsgeschwindigkeit Vorrang vor der Kostenoptimierung einräumen, sind Cloud-verwaltete Optionen oft der richtige Ansatzpunkt.
Vektorspeicher in der RAG-Architektur
Rolle in der RAG-Architektur Komponenten
Retrieval-Augmented Generation (RAG) ist das vorherrschende Paradigma für den Einsatz von LLMs mit benutzerdefinierten, proprietären Daten. Laut dem Bericht "2024 State of Generative AI" von Menlo Ventures macht RAG inzwischen 51 % der KI-Implementierungen in Unternehmen aus, gegenüber 31 % im Vorjahr. In ähnlicher Weise fand Databricks heraus, dass 70 % der Unternehmen, die LLMs einsetzen, Vektordatenbanken und Retrievalsysteme nutzen, um ihre Basismodelle zu erweitern.
Vektorspeicher sind das Herzstück eines jeden RAG-Systems. So funktioniert die Pipeline:
Dateneingabe:
- Quelldokumente (PDFs, Wikis, Datenbanken) werden in Segmente von überschaubarer Größe zerlegt.
- Jedes Stück wird durch ein Einbettungsmodell geleitet, um einen Vektor zu erzeugen.
- Die Vektoren werden im Vektorspeicher gespeichert und für einen schnellen Abruf indiziert.
Abfrage zur Zeit der Abfrage:
- Dasselbe Einbettungsmodell wird auf die Anfrage des Benutzers angewandt.
- Der Vektorspeicher führt eine Ähnlichkeitssuche durch und gibt die Top-k relevantesten Chunks zurück.
- Diese Chunks werden in die Eingabeaufforderung des LLM als Kontext eingefügt.
- Der LLM generiert eine Antwort, die auf Ihren tatsächlichen Daten basiert - nicht nur auf dem Training.
Diese Architektur löst eines der kritischsten Probleme im Bereich der künstlichen Intelligenz in Unternehmen: LLM-Antworten müssen genau und aktuell sein und auf verifizierten Informationen beruhen.
Verbesserung der Qualität der Datenabfrage
Die Qualität Ihres RAG-Systems hängt in hohem Maße von den Entscheidungen ab, die getroffen werden, bevor eine einzelne Benutzeranfrage eintrifft. Im Einzelnen:
- Chunking-Strategie: Zu kleine Chunks verlieren den Kontext. Zu große Chunks führen zu Rauschen. Satzorientiertes Chunking oder rekursives Zeichensplitting übertrifft in der Regel naives Chunking mit fester Größe.
- Filterung von Metadaten: Die Kennzeichnung von Chunks mit Metadaten (Datum, Dokumenttyp, Autor, Abteilung) ermöglicht eine Vorfilterung vor der Ähnlichkeitssuche. Dadurch wird der Suchraum eingegrenzt und die Relevanz erheblich verbessert.
- Hybride Suche: Die Kombination aus dichter Vektorsuche und spärlicher Schlagwortsuche (BM25) führt häufig zu besseren Ergebnissen als jeder Ansatz für sich. Diese Technik erfasst sowohl die semantische Relevanz als auch die exakte Übereinstimmung von Schlüsselwörtern.
- Modelle zur Neueinstufung: Nach dem ersten Abruf kann ein Cross-Encoder-Modell die Ergebnisse neu bewerten und neu anordnen, um eine höhere Präzision zu erzielen, bevor sie den LLM erreichen.
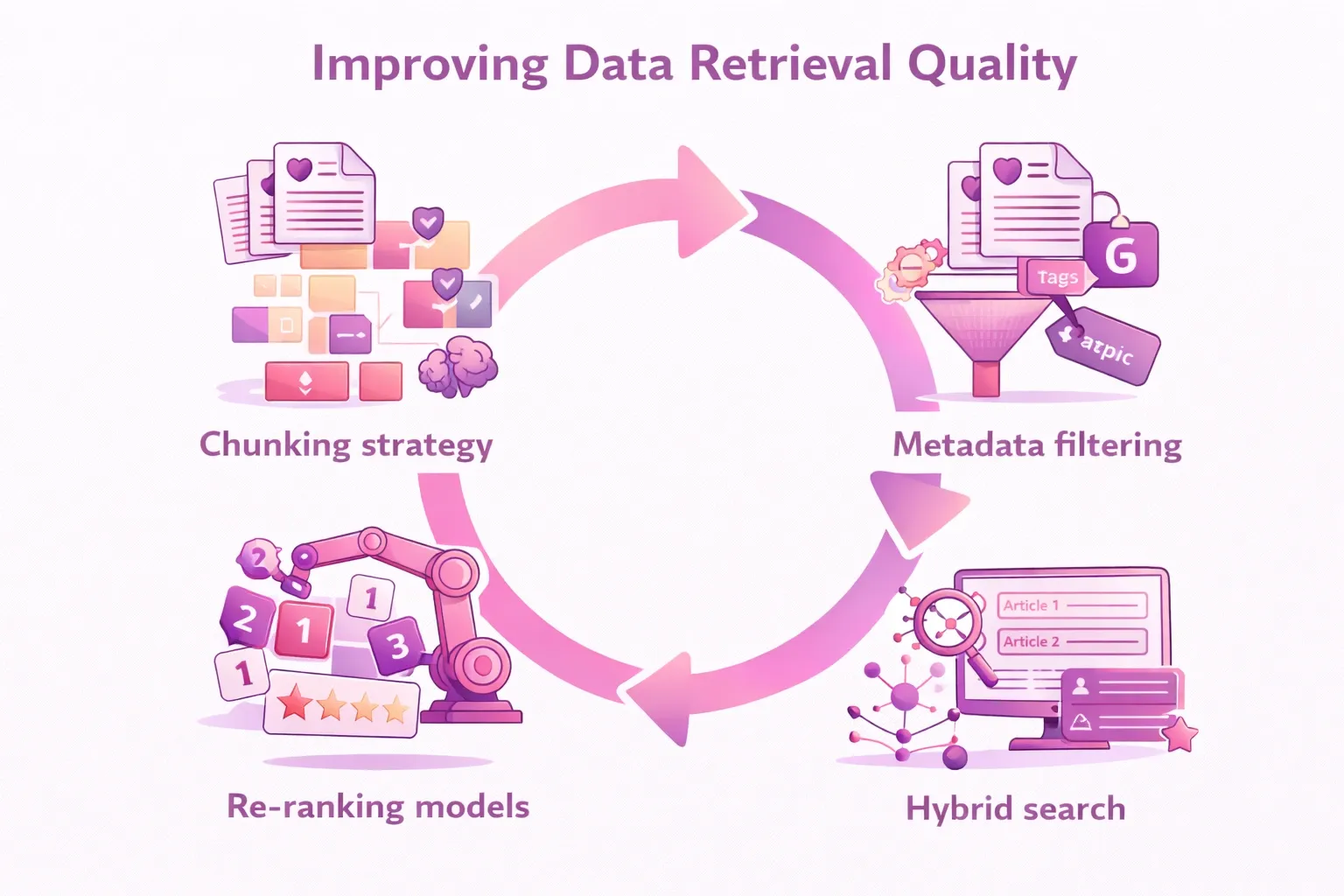
Dies sind keine theoretischen Optimierungen. Sie machen den Unterschied zwischen einem RAG-System, dem Produktionsteams vertrauen, und einem, das sie im Stillen aufgeben. Wenn Sie tiefer in fortgeschrittene RAG-Optimierungsstrategien eintauchen möchten, finden Sie in Escape the Naiveness of RAG von Intertec Best Practices für Chunking, Retrieval-Tuning und Vektorspeicherverwaltung in der Produktion.
Auswahl der richtigen Vektordatenbank
Welche Vektordatenbank ist die beste?
Die ehrliche Antwort? Es kommt darauf an. Es gibt keine universell "beste" Vektordatenbank - nur die beste für Ihre spezifische Arbeitslast. Hier sind die wichtigsten Bewertungskriterien, die wir CTOs für diese Entscheidung empfehlen:
- Indizierungsleistung - Wie schnell kann das System neue Vektoren einlesen und indizieren? Dies ist wichtig für Systeme mit kontinuierlicher Dateneingabe.
- Abfragelatenz - Wie hoch ist die p95-Latenz für die Ähnlichkeitssuche bei dem von Ihnen erwarteten Abfragevolumen?
- Horizontale Skalierbarkeit - Kann das System über mehrere Knoten verteilt werden, wenn Ihr Datensatz auf Milliarden von Vektoren anwächst?
- Filterfunktionen - Unterstützt das System eine effiziente Vorfilterung oder Nachfilterung mit Metadaten? Einige Systeme können dies viel besser als andere.
- Integration mit Ihrem KI-Stack - Lässt sich das System nativ mit LangChain, LlamaIndex, Ihrem Einbettungsanbieter und Ihrer Orchestrierungsschicht integrieren?
Überlegungen zur Produktion
Die Auswahl eines Vektorspeichers ist nur der Anfang. Der Einsatz in der Produktion bringt zusätzliche Probleme mit sich, die von den Teams häufig unterschätzt werden:
- Überwachung und Beobachtbarkeit - Verfolgen SieAbruflatenz, Indexfrische und Abfrageerfolgsraten. Ohne diese Transparenz verschlechtert sich die Abrufqualität unmerklich.
- Strategie zur Datenaktualisierung und Neueinbettung - Wennsich Ihre Quelldokumente ändern, benötigen Sie eine klare Strategie zur Aktualisierung der Einbettungen. Veraltete Vektoren führen zu überholten oder falschen Antworten.
- Sicherheit und Mandantenfähigkeit - InUnternehmensumgebungen sind Namespace-Isolierung und Zugriffskontrolle nicht verhandelbar. Stellen Sie sicher, dass Ihr Vektorspeicher die Datentrennung auf Mandantenebene unterstützt.
- Kompromisse zwischen Kosten und Leistung - Bei derSkalierung summieren sich die Speicher- und Abfragekosten schnell. Bewerten Sie die Kosten pro Million Abfragen zusammen mit rohen Leistungsbenchmarks.
Häufige Fallstricke bei der Implementierung von Vektorspeichern
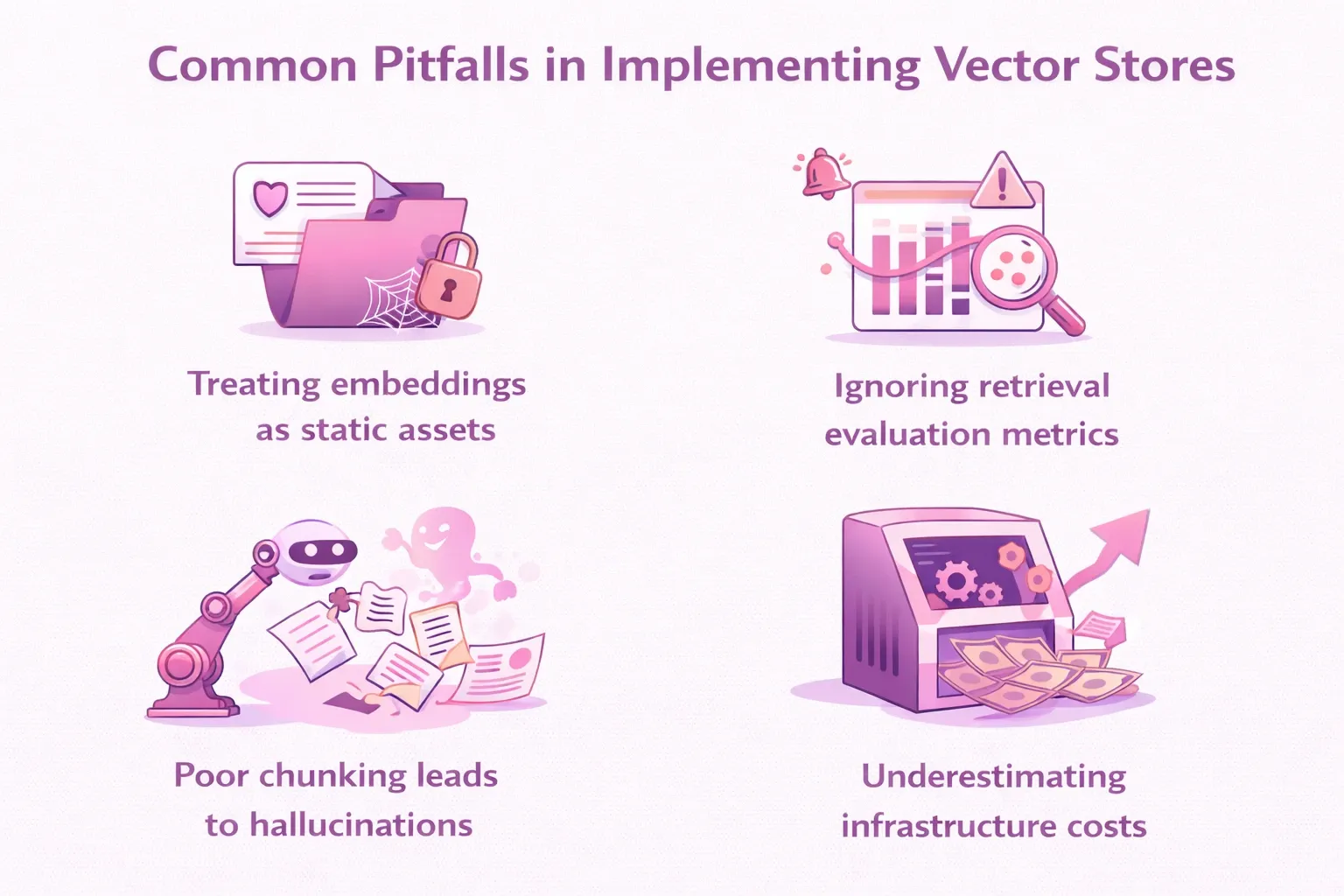
Wir haben gesehen, dass Teams immer wieder die gleichen Fehler machen. Wenn Sie diese Fehler im Voraus kennen, können Sie sich monatelange vergebliche Arbeit sparen.
Ein kritischer Fehler ist es, Einbettungen als statische Assets zu behandeln. Einbettungen werden von einem bestimmten Modell zu einem bestimmten Zeitpunkt erzeugt. Wenn Ihr Einbettungsmodell aktualisiert wird - oder wenn sich Ihre Quelldaten ändern - können Ihre Vektoren nicht mehr mit den Abfragen übereinstimmen, was die Abrufqualität unmerklich verschlechtert.
Das Ignorieren von Metriken zur Bewertung des Abrufs ist ebenfalls weit verbreitet. Teams verwenden enorme Anstrengungen auf die LLM-Feinabstimmung, setzen aber Retrieval-Pipelines ohne systematische Bewertung ein. Tools wie RAGAS bieten referenzfreie Metriken zur Messung der Abrufpräzision, der Wiederauffindbarkeit und der Treffsicherheit. Nutzen Sie sie.
Schlechtes Chunking führt zu Halluzinationen. Wenn Ihre Chunks den für die Beantwortung einer Frage erforderlichen Umgebungskontext verlieren, wird der LLM die Lücke mit plausibel klingenden, aber erfundenen Informationen füllen. Kontextbewusstes Chunking ist kein Nice-to-have. Es ist ein Sicherheitsaspekt.
Die Unterschätzung der Infrastrukturkosten ist ein Budgetrisiko. Die Speicherung von Vektoren in großem Maßstab ist teuer, insbesondere bei Datensätzen mit Milliarden von Vektoren. Kalkulieren Sie dies frühzeitig ein und berücksichtigen Sie die Kosten für die Neuindizierung, die bei der Aktualisierung von Einbettungsmodellen erheblich sein können.
Schlussfolgerung: Vektordatenbanken als Kernbestandteile moderner KI-Architekturen
Wir haben eine Menge Stoff behandelt. Lassen Sie es uns zusammenfassen.
Vektorspeicher sind nicht länger eine experimentelle Infrastruktur - sie sind die Grundlage jeder ernsthaften KI-Anwendung, die Antworten in realen Daten abrufen, kontextualisieren und fundieren muss. Sie ermöglichen eine Form des Datenabrufs, die herkömmliche Datenbanken einfach nicht bieten können: semantisch, probabilistisch und eng an die Denkweise von Sprachmodellen angelehnt.
Wenn sie durchdacht implementiert werden, verwandeln Vektorspeicher RAG-Pipelines von Proof-of-Concepts in Produktionssysteme, die tatsächlich Wert liefern. Die Dynamik in den Unternehmen bestätigt diese Entwicklung. Laut Menlo Ventures stieg die Akzeptanz von RAG innerhalb eines einzigen Jahres von 31 % auf 51 % der KI-Implementierungen in Unternehmen. Die Nutzung von Vector-Datenbanken stieg laut Databricks im Jahresvergleich um 377 %. Dies sind keine bescheidenen Zuwächse. Es sind Signale dafür, dass eine Kategorie zur Kerninfrastruktur wird.
Mit der zunehmenden Verbreitung von KI stellt sich für CTOs nicht mehr die Frage , ob sie in Vektorspeicher investieren sollen. Vielmehr stellt sich die Frage, in welchen, wie man die Architektur gestaltet und wie man die Leistung im Laufe der Zeit bewertet. Wenn Sie diese Entscheidungen richtig treffen, werden Ihre KI-Systeme fundiert, skalierbar und vertrauenswürdig sein. Wenn Sie diese Entscheidungen falsch treffen, wird Sie keine noch so gute LLM-Feinabstimmung retten.
Die Grundlage ist wichtig. Machen Sie es solide.
Hat dieser Artikel dazu beigetragen, zu klären, wie Vektorspeicher funktionieren und wie Sie den richtigen für Ihren KI-Stack auswählen? Wenn ja, sollten Sie ihn mit Kollegen und Teammitgliedern teilen, die vor ähnlichen Entscheidungen stehen. Lassen Sie uns gemeinsam die Messlatte höher legen.