Amazon Redshift ist ein vollständig verwalteter Data-Warehouse-Service in der Cloud im Petabyte-Bereich, mit dem Sie Ihre Daten nutzen können, um neue Erkenntnisse für Ihr Unternehmen und Ihre Kunden zu gewinnen. Bei Intertec nutzen wir Amazon Redshift, um Berichte über alle verfügbaren Datenquellen zu erstellen und unser eigenes Data Warehouse zu hosten.
Im folgenden Artikel werden wir uns eine der vielen Datenquellen, die wir verwalten, genauer ansehen.
Bei dieser speziellen Datenquelle handelt es sich um eine Sammlung von Anwendungsprotokollen, die wir verarbeiten und dann die Nutzungsstatistiken in einem Dashboard anzeigen. Die im Dashboard angezeigten Daten befinden sich in Redshift und werden aktualisiert, sobald neue Daten eintreffen.
Nachdem der Implementierungsprozess abgeschlossen war, stellten wir jedoch fest, dass uns jede Woche Daten für einen bestimmten Zeitraum fehlten. Um herauszufinden, was los ist, führten wir eine Untersuchung durch und fanden heraus, dass die fehlenden Daten auf die Nichtverfügbarkeit des Redshift-Clusters zu diesem bestimmten Zeitpunkt zurückzuführen sind.
Aktuelle Architektur
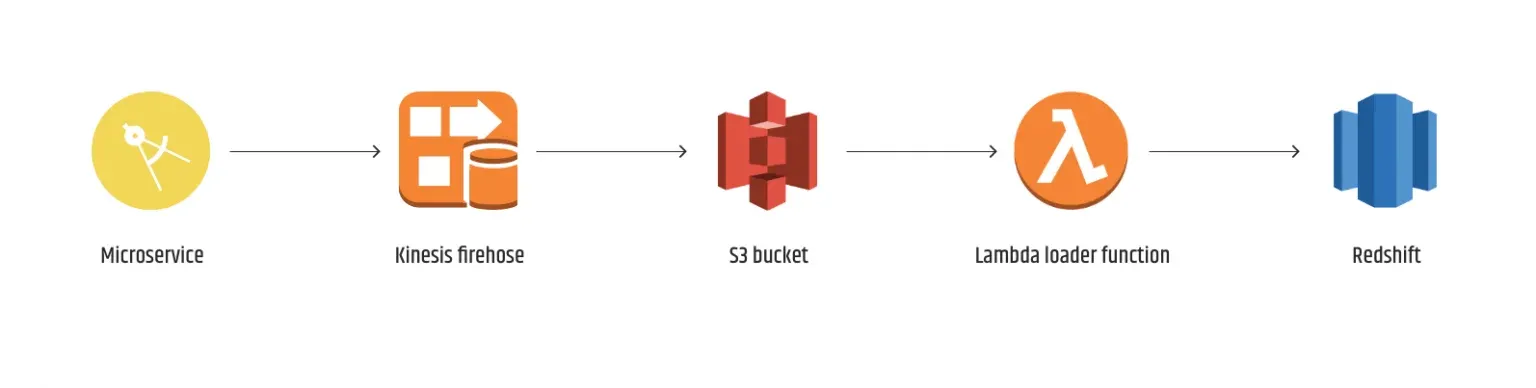
Wie in der obigen Abbildung zu sehen ist, speist ein Microservice Anwendungsprotokolle in einen Kinesis-Firehose ein, der sie alle 300 Sekunden oder 15 MB sammelt und in S3 ablegt.
Von dort aus wird eine Lambda-Funktion so konfiguriert, dass sie immer dann ausgelöst wird, wenn eine neue Datei im angegebenen S3-Bucket erstellt wird. Die Lambda-Funktion führt dann einen COPY-Befehl für die Datei aus und speichert sie in der Redshift-Tabelle.
Was haben wir als nächstes getan?
Das Geschäftsziel bestand darin, die Anwendungsnutzungsstatistiken in einem Dashboard (fast) in Echtzeit darzustellen.
Wir wissen, dass Redshift ein geplantes Wartungsfenster von 30 Minuten pro Woche hat, d. h., wenn es in diesen 30 Minuten Upgrades gibt, ist der Cluster für die Lambda-Funktion nicht erreichbar. Dies führt dazu, dass Daten im Dashboard fehlen, was zu unvollständigen Ergebnissen führt.
Unsere Lösung?
Wir speichern irgendwo eine Liste der fehlgeschlagenen Dateien, um sie später zu verarbeiten. Da das Wartungsfenster unseres Redshift-Clusters sonntags von 05:30 - 06:00 Uhr ist, werden wir versuchen, alle Dateien, die nach 06:00 Uhr fehlgeschlagen sind, jeden Sonntag zu laden.
Wie wurde die Implementierung durchgeführt?
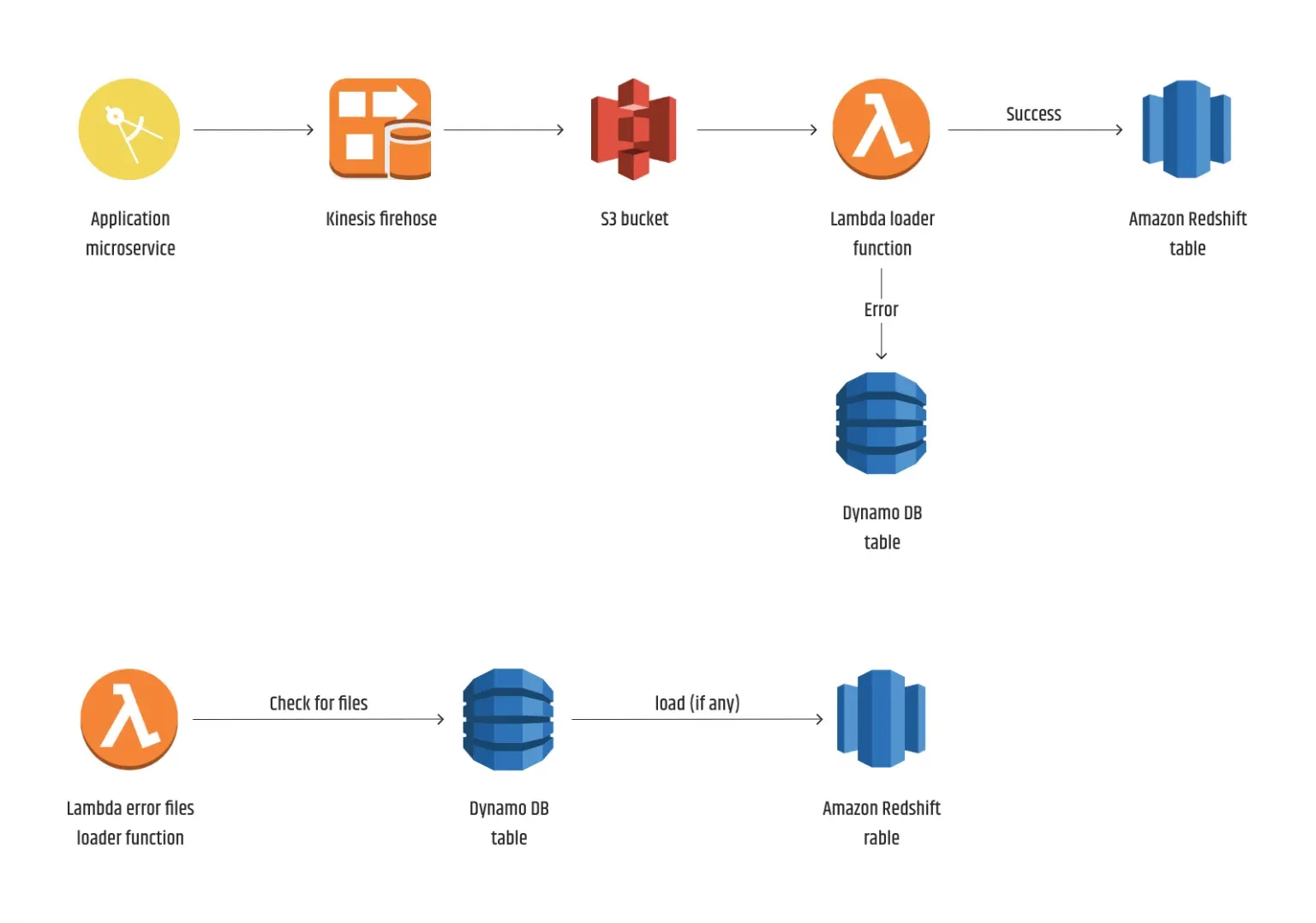
Das bestehende Lambda, das das Laden durchführt, wird erweitert, um alle Fehlschläge in eine DynamoDB-Tabelle zu schreiben:
try: cur = con.cursor() cur.execute(""" COPY command... """) cur.close() except Exception as e: dynamodb = boto3.client('dynamodb') dynamodb.put_item(TableName='copy-errors', Item={ 'file_name':{'S': file_name}, 'error':{'S': e }, 'timestamp':{'S': datetime.strftime(datetime.now(),"%Y-%m-%d %H:%M:%S")} } )
Die Lambda-Funktion, die nach dem geplanten Wartungszeitraum ausgeführt wird, durchläuft die Elemente in der DynamoDB-Tabelle und erstellt eine Manifestdatei, die die Liste der zu ladenden Dateien enthält:
for i in response['Items']: file_list.append({'url': ''+i['file_name']}) data = {"entries": file_list} s3.put_object(Bucket='bucket',Key='manifest_file.manifest',Body=json.dumps(data))
Anschließend wird ein Kopierbefehl für diese Manifestdatei ausgeführt. Wenn es keine Fehler gibt, werden die Elemente aus DynamoDB entfernt:
for file in raw_file_list: table.delete_item(Key={ 'file_name': file })
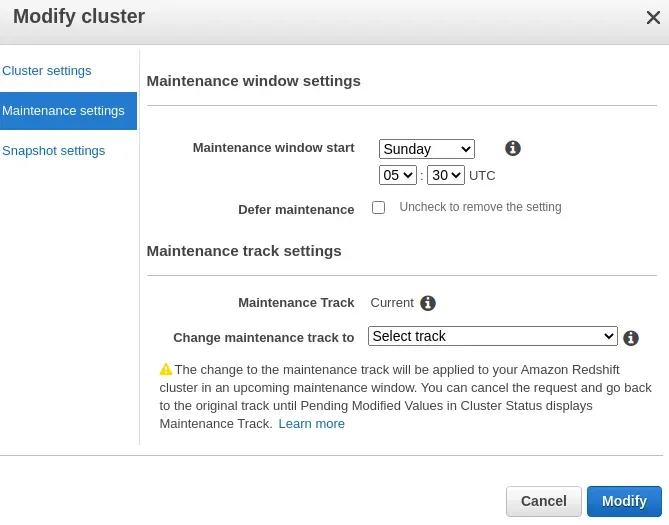
Der Lambda wird mithilfe von Cron so geplant, dass er kurz nach dem Wartungsfenster ausgeführt wird. Diese Information ist in der AWS-Konsole zu finden. Das Wartungsfenster wird auch pro Cluster geändert:
Architekturdiagramm nach Einbeziehung von DynamoDB
Zum Schluss
Unsere Ingenieure sind ständig bemüht, neue Wege zu finden, um Unternehmen und Unternehmenskunden dabei zu helfen, die komplexen Probleme zu lösen, die während ihrer Reise zur digitalen Transformation immer wieder auftauchen.
In diesem speziellen Fall konnte die Lambda-Funktion nicht so eingerichtet werden, dass sie auf die Verfügbarkeit des Clusters wartet, und wir mussten einen Weg finden, die Ausführung irgendwie zu verschieben. Diese einfache Implementierung der Fehlerbehandlung in serverlosen Anwendungen ist nur ein Ansatz, wenn man über begrenzte Ressourcen verfügt. Wie würden Sie vor diesem Hintergrund vorgehen?
Wenn Sie Teil eines Teams sein wollen, das sich täglich neuen Herausforderungen stellt und ständig daran arbeitet, neue Wege zu finden, um komplexe Probleme zu lösen, dann sollten Sie sich unsere aktuellen Stellenangebote ansehen.