What is Retrieval Augmented Generation?
Retrieval Augmented Generation Explained
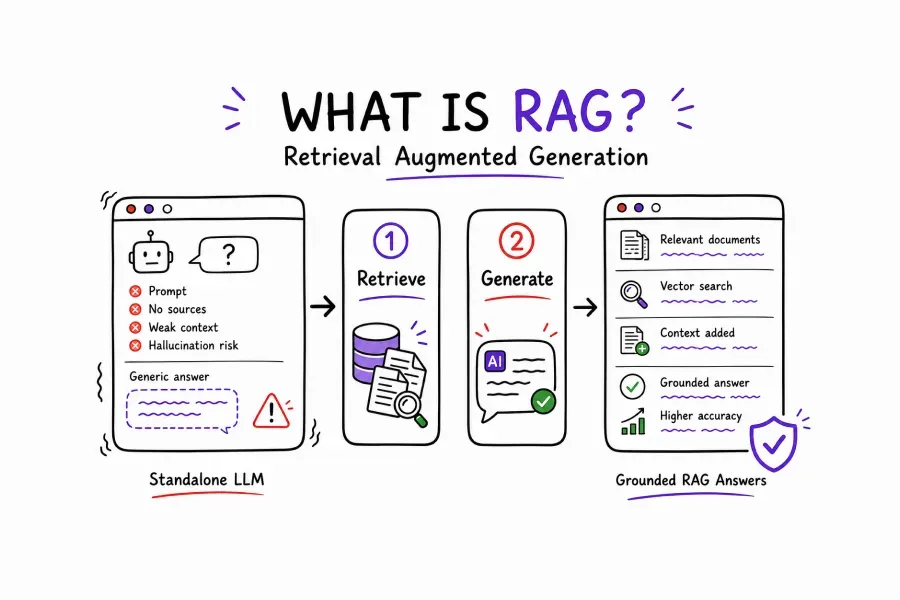
At its core, Retrieval Augmented Generation (RAG) is an AI framework that combines the power of a generative language model with the precision of a real-time information retrieval system. Instead of relying solely on what the model memorized during training, RAG gives the model access to an external knowledge source — and it queries that source every single time a user asks a question.
Think of it this way. A standard LLM is like a brilliant consultant who read everything up until the day they joined your company — but never read another document after that. RAG, however, is like giving that consultant a live search engine connected to your entire knowledge base. Now they can answer questions using the most current, relevant information available.
The relationship between Natural Language Processing, Large Language Models, and retrieval systems is what makes this architecture so powerful. NLP handles understanding and generating human language. LLMs provide the reasoning and synthesis capability. Retrieval systems supply the current, context-specific knowledge. Together, these three pillars form the backbone of what Retrieval Augmented Generation is in practice.
"One of the most important recent developments in making large language models genuinely useful in production environments is RAG." — Douwe Kiela
What is RAG in LLM — A Simple Example
Let's make this concrete. Imagine you deploy an AI assistant for your internal IT helpdesk. An employee asks: "What's the process for requesting a new software license under our updated 2024 procurement policy?"
A standard LLM would either hallucinate a process, admit it doesn't know, or pull something from its generic training data that has nothing to do with your specific company policy.
A RAG-powered assistant, however, does something different. It first retrieves the most relevant chunks from your internal documentation — your procurement policy PDF, for instance — and then generates a precise, grounded answer based on those retrieved documents. The model isn't guessing. It's synthesizing real, current information you've provided.
This is the defining difference. Answering from training data = generalization. Answering from retrieved documents = specificity and accuracy. For enterprise RAG AI applications, this distinction is everything.
Common enterprise scenarios where this matters include:
- HR teams querying internal policy documents
- Legal teams searching across thousands of contract templates
- Sales teams pulling up-to-date product specs and pricing sheets
- Compliance teams accessing real-time regulatory changes
How Retrieval Augmented Generation Works
Retrieval Augmented Generation Architecture
Understanding the retrieval augmented generation architecture is essential for any leader evaluating or implementing this technology. The system has five key components, and each plays a distinct role.
1. Data Ingestion and Document Processing
First, your knowledge sources — PDFs, databases, wikis, emails, reports — get ingested into the system. These documents are cleaned, chunked into manageable segments, and prepared for indexing. The quality of this step directly impacts everything downstream. Garbage in, garbage out is painfully true here.
2. Embedding Models
Next, each text chunk is converted into a numerical representation called an embedding. Embeddings capture the semantic meaning of text, not just keywords. Two sentences that mean the same thing will have similar embeddings, even if they use different words. This is what makes semantic search so powerful.
3. Vector Stores or Search Index
These embeddings get stored in a vector database — purpose-built systems like Pinecone, Weaviate, or pgvector. When a user submits a query, the system converts that query into an embedding and performs a similarity search. The most semantically relevant document chunks come back as results.
4. Retrieval Pipeline
The retrieval pipeline orchestrates the search. It takes the user's query, generates its embedding, queries the vector store, and returns the top-N most relevant chunks. Advanced pipelines include re-ranking steps, metadata filtering, and hybrid search (combining vector and keyword search).
5. Generative Model Response
Finally, the retrieved context gets injected into the prompt alongside the user's original question. The LLM then generates a response that is grounded in that specific context. The model doesn't need to "know" the answer from training — it reads it from the retrieved chunks and synthesizes a response.
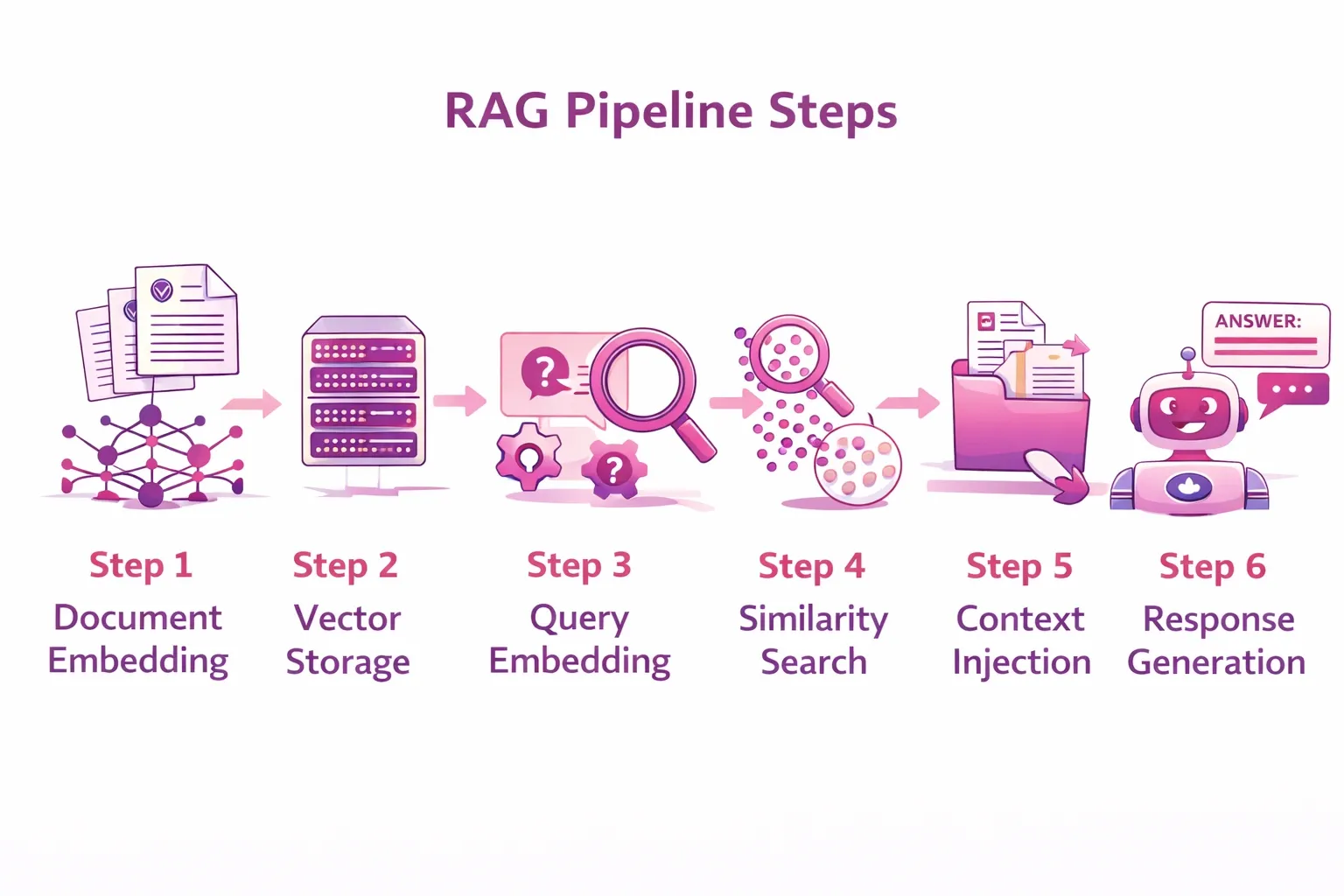
The RAG Pipeline Step by Step
Let's trace the full journey of a single query through a RAG system:
- Step 1 — Document Embedding: Your internal documents are chunked (e.g., 500 tokens per chunk) and converted into vector embeddings using a model like OpenAI's text-embedding-ada-002 or a self-hosted alternative.
- Step 2 — Vector Storage: Those embeddings are stored in a vector database alongside metadata like document title, date, and source URL.
- Step 3 — Query Embedding: When a user asks a question, that question is also converted into an embedding using the same model.
- Step 4 — Similarity Search: The system finds the top document chunks whose embeddings are most similar to the query embedding.
- Step 5 — Context Injection: The retrieved chunks are passed to the LLM as part of the prompt: "Based on the following context: [retrieved chunks], answer this question: [user query]."
- Step 6 — Response Generation: The LLM generates a grounded, accurate response using the retrieved context.
According to Gartner, by 2026, more than 80% of enterprises will have used generative AI APIs or deployed generative AI-enabled applications in production, and RAG architectures are increasingly the standard approach for grounding these applications in real data.
RAG vs Fine-Tuning: Choosing the Right Approach
Retrieval Augmented Generation vs Fine-Tuning
When leaders first explore how to customize an LLM for their business, they often face a key decision: retrieval augmented generation vs fine-tuning. Both approaches have their place, but they solve fundamentally different problems.
Fine-tuning means taking a base model and further training it on your proprietary data. This modifies the model's actual weights. It's powerful for teaching the model a specific writing style, tone, or specialized domain vocabulary. However, it's expensive, slow to update, and still doesn't prevent hallucinations on truly novel queries.
RAG, by contrast, doesn't touch the model's weights at all. Instead, it dynamically retrieves relevant information at inference time. This means your knowledge base can be updated continuously — upload a new document today, and the AI can answer questions about it tomorrow. No retraining required.
Here's a practical comparison:
| Aspect | Fine-Tuning | Retrieval-Augmented Generation (RAG) |
| Cost | Requires significant compute resources and labeled training data. | Generally cheaper to maintain and update. |
| Speed of Updates | Updating the model can take days or weeks because it requires retraining. | Knowledge base updates can happen in minutes without retraining the model. |
| Transparency | Opaque—it's difficult to see exactly how the model arrived at an answer. | Transparent—you can see which documents were retrieved to generate the response. |
| Accuracy on Fresh Data | Knowledge is frozen at the time of training and may become outdated. | Excels with fresh data since it retrieves up-to-date information from the knowledge base. |
| Stylistic Consistency | Strong—ideal when consistent tone or writing style is required. | Weaker for strict stylistic control since responses depend on retrieved content. |
For most enterprise use cases involving dynamic knowledge — internal policies, product data, and regulatory updates — RAG is the more practical and scalable choice.
Hybrid Approaches: The Best of Both Worlds
Increasingly, sophisticated AI teams are combining both approaches. They fine-tune a base model on domain-specific language and writing style, and then layer a RAG system on top to inject real-time knowledge. For example, a healthcare AI might be fine-tuned on clinical language conventions but use RAG to retrieve the latest drug interaction databases or clinical guidelines.
Modern AI frameworks like LangChain, LlamaIndex, and Haystack make it straightforward to build these layered architectures. They provide out-of-the-box components for vector stores, retrieval pipelines, and LLM integration — dramatically reducing the engineering burden for teams implementing what is Retrieval Augmented Generation in production.
Real-World Use Cases of Retrieval Augmented Generation
Enterprise Knowledge Assistants
The most immediate and high-value application of RAG AI applications is the enterprise knowledge assistant. These are AI systems that can answer employee questions by drawing on internal documentation — HR policies, IT guides, onboarding materials, and financial procedures.
Companies like Glean and Guru have built entire product lines around this concept. Rather than employees spending hours searching for information across SharePoint, Confluence, Google Drive, and email, a RAG-powered assistant retrieves and synthesizes the right answer in seconds.
Similarly, customer support knowledge bases benefit enormously from RAG. Support agents — or even automated chatbots — can pull from product manuals, troubleshooting guides, and support ticket history to resolve issues faster and with greater accuracy.
Industry-Specific AI Applications
Healthcare
In healthcare, RAG powers research assistants that help clinicians retrieve relevant studies, patient history patterns, and clinical protocols. Recent research in Nature Digital Medicine emphasizes that AI-assisted clinical tools can significantly improve diagnostic accuracy, provided they are grounded in current, reliable data. Retrieval-Augmented Generation (RAG) has emerged as the leading architecture to provide this grounding by connecting models to live medical databases.
Financial Services
Financial analysts use RAG-powered tools to query earnings reports, SEC filings, market research, and internal models. Instead of manually reading 200 pages of a 10-K filing, an analyst can ask a RAG system: "What are the top three risk factors mentioned in Q3 earnings?" and in a matter of seconds get a grounded, cited response.
Legal
Law firms and legal departments are deploying RAG to search across case law, contract repositories, and regulatory databases. Tools like Harvey AI and CoCounsel from Thomson Reuters leverage retrieval-augmented generation to help lawyers research precedents and draft documents faster. However, the ability to cite exact sources makes RAG especially critical in legal contexts where accuracy is non-negotiable.
Developer and Engineering Tools
For engineering teams, RAG enables powerful code assistants that can search internal repositories, README files, API documentation, and architecture decision records. Instead of relying on generic public documentation, developers get answers grounded in the company's actual codebase and standards.
DevOps teams use RAG for incident response knowledge retrieval — pulling relevant runbooks and post-mortems in real time during an outage. Additionally, documentation automation tools use RAG to summarize and synthesize internal knowledge into updated docs without requiring engineers to write everything manually.
Challenges and Best Practices for Implementing RAG
Data Quality and Retrieval Accuracy
The single biggest predictor of a successful RAG implementation is data quality. If your underlying documents are messy, inconsistent, or outdated, the retrieval system will surface poor-quality context, and even the best LLM will struggle to generate accurate answers from bad inputs.
Here are the most important best practices we recommend:
- Chunking strategy matters: Chunks that are too large dilute relevance; chunks that are too small lose context. Experiment with 300–600 token chunks with overlapping windows.
- Metadata tagging: Tag every document chunk with source, date, department, and access level. This enables powerful filtered retrieval and helps with auditability.
- Data freshness: Establish clear pipelines for updating your knowledge base. Stale documents are worse than no documents in high-stakes domains.
- Retrieval evaluation: Use evaluation frameworks like RAGAS to measure retrieval precision, recall, and faithfulness of generated answers.

Architecture and Infrastructure Considerations
Choosing the right AI framework and vector database is a strategic decision, not just a technical one. The vector database you choose needs to scale with your data volume and query frequency. Popular options include:
- Pinecone: Fully managed, easy to scale, strong for production workloads.
- Weaviate: Open-source with rich filtering capabilities and hybrid search support.
- pgvector: PostgreSQL extension — ideal for teams already using Postgres who want to minimize infrastructure sprawl.
- Qdrant: High-performance, open-source, strong for complex filtering use cases.
Beyond the database, latency management is critical. Every RAG query adds retrieval latency on top of the LLM generation time. For customer-facing applications, this trade-off needs careful tuning. Caching strategies, approximate nearest neighbor (ANN) search algorithms, and asynchronous retrieval pipelines all help reduce latency without sacrificing retrieval quality.
Finally, monitoring is non-negotiable. Implement logging for both retrieval results and generated responses. Track metrics like retrieval hit rate, answer faithfulness, and user satisfaction. Without visibility into how the system performs in production, you cannot systematically improve it.
Why RAG Is Becoming a Standard AI Architecture
Let's look at the bigger picture. We're at an inflection point in enterprise AI adoption. According to McKinsey's 2024 State of AI report, 65% of organizations are now regularly using generative AI, moving from experimentation to production requires solving the reliability problem that plagued early deployments.
RAG directly addresses that reliability problem. It bridges the gap between static AI models trained on historical data and the dynamic, constantly changing knowledge environments that real enterprises operate in. It enables AI systems that are not just smart, but also grounded, auditable, and updatable.
Furthermore, from a governance and compliance perspective, RAG provides something that pure LLMs cannot: traceability. When an AI answer can be traced back to a specific document chunk, with a source citation, organizations can audit AI behavior and identify when the system needs updating. This matters enormously in regulated industries like finance, healthcare, and legal services.
As we look ahead, the evolution of RAG is accelerating. Advances like Agentic RAG — where AI agents autonomously decide which tools and knowledge sources to query — are expanding the architecture's capabilities significantly. Multi-modal RAG, which retrieves not just text but images, tables, and structured data, is also emerging rapidly.
The organizations that invest in robust RAG infrastructure today are building a durable competitive advantage. They're creating AI systems that get smarter every time they add new knowledge — without expensive retraining cycles. And they're doing it in a way that keeps humans in control, with full visibility into what the AI knows and where it learned it.
Key Takeaways
- What is Retrieval Augmented Generation? It's an AI framework that combines real-time information retrieval with generative language models to produce accurate, grounded responses.
- Why does it matter? It solves the core limitations of standalone LLMs: hallucinations, outdated knowledge, and lack of proprietary context.
- How does it work? Documents are embedded and stored in a vector database. At query time, relevant chunks are retrieved and injected into the LLM prompt.
- RAG vs fine-tuning: RAG is more scalable and cost-effective for dynamic enterprise knowledge. Fine-tuning is better for stylistic or domain-language alignment.
- Real-world impact: From healthcare to finance to legal to DevOps, RAG AI applications are delivering measurable value across industries today.
Found This Useful? Here's What to Do Next.
If this article gave you a clearer picture of what is Retrieval Augmented Generation and how it applies to your organization's AI strategy — we'd love for you to share it. Forward it to a colleague who's evaluating enterprise AI. Share it on LinkedIn with your perspective on where RAG fits in your industry. Like it, comment on it, and start a conversation.
The more leaders understand these foundational AI architectures, the better the decisions organizations make when deploying AI in production. So help us spread the knowledge. Your share could be the nudge someone in your network needs to build AI systems that actually work.