Warum KI mehr als nur große Sprachmodelle braucht
Seien wir ehrlich. Als die meisten von uns zum ersten Mal mit großen Sprachmodellen experimentierten, waren wir überwältigt. Sie beantworteten komplexe Fragen, entwarfen ausgefeilte E-Mails und fassten dichte Berichte in Sekundenschnelle zusammen. Die Begeisterung verflog jedoch schnell, als wir begannen, diese Tools in echten Unternehmen einzusetzen.
Plötzlich wurden die Lücken offensichtlich. Die KI wusste nichts über unser neuestes Produktupdate. Sie gab uns selbstbewusst veraltete gesetzliche Vorgaben. Sie erfand interne Prozesse, die nie existierten. Das waren keine kleinen Bugs. Es waren grundlegende Beschränkungen, die in die Funktionsweise eigenständiger LLMs eingebaut sind.
Hier ist die harte Wahrheit: Ein traditionelles LLM ist ein statisches System. Es lernt aus einem riesigen Datensatz bis zu einem bestimmten Stichtag, und dann hört es auf zu lernen. Laut IBM Research besteht eine der größten Herausforderungen bei generativer KI darin, dass Modelle häufig Ergebnisse produzieren, die zwar plausibel klingen, aber faktisch falsch sind - ein Phänomen, das gemeinhin als Halluzination bezeichnet wird.
Für Führungskräfte und Teams für die digitale Transformation ist dies kein akademisches Problem. Es ist ein Geschäftsrisiko. Stellen Sie sich vor, dass eine KI für den Kundensupport eine Produktgarantie angibt, die nicht mehr existiert. Oder ein KI-Assistent im Finanzwesen, der Compliance-Regeln aufruft, die vor zwei Quartalen geändert wurden.
Genau hier kommt Retrieval Augmented Generation - oder RAG - ins Spiel. Was also ist Retrieval Augmented Generation, und warum wird es schnell zu einer der wichtigsten Architekturen in der Unternehmens-KI? Schauen wir uns das gemeinsam an.
Was ist Retrieval Augmented Generation?
Retrieval Augmented Generation Erklärt
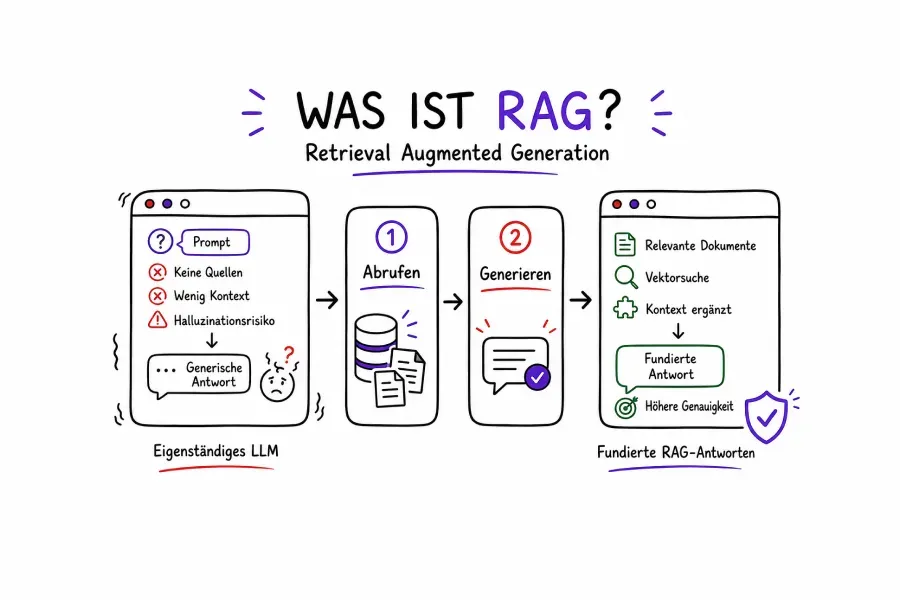
Im Kern ist Retrieval Augmented Generation (RAG) ein KI-Framework, das die Leistung eines generativen Sprachmodells mit der Präzision eines Echtzeit-Informationsabfragesystems kombiniert. Anstatt sich ausschließlich auf das zu verlassen, was das Modell während des Trainings gespeichert hat, gibt RAG dem Modell Zugriff auf eine externe Wissensquelle - und fragt diese Quelle jedes Mal ab, wenn ein Benutzer eine Frage stellt.
Stellen Sie es sich so vor. Ein Standard-LLM ist wie ein brillanter Berater, der bis zu dem Tag, an dem er in Ihr Unternehmen eintrat, alles gelesen hat - aber danach nie wieder ein Dokument gelesen hat. RAG hingegen ist so, als würde man diesem Berater eine Live-Suchmaschine zur Verfügung stellen, die mit Ihrer gesamten Wissensbasis verbunden ist. Jetzt kann er Fragen mit den aktuellsten und relevantesten verfügbaren Informationen beantworten.
Die Beziehung zwischen natürlicher Sprachverarbeitung, großen Sprachmodellen und Retrievalsystemen macht diese Architektur so leistungsfähig. NLP kümmert sich um das Verstehen und Erzeugen menschlicher Sprache. LLMs bieten die Fähigkeit zur Schlussfolgerung und Synthese. Retrievalsysteme liefern das aktuelle, kontextspezifische Wissen. Zusammen bilden diese drei Säulen das Rückgrat dessen, was Retrieval Augmented Generation in der Praxis ist.
"RAG ist eine der wichtigsten Entwicklungen der letzten Zeit, um große Sprachmodelle in Produktionsumgebungen wirklich nützlich zu machen." - Douwe Kiela
Was ist RAG im LLM - ein einfaches Beispiel
Lassen Sie uns das konkret machen. Stellen Sie sich vor, Sie setzen einen KI-Assistenten für Ihren internen IT-Helpdesk ein. Ein Mitarbeiter fragt: "Wie ist der Prozess zur Beantragung einer neuen Softwarelizenz gemäß unserer aktualisierten Beschaffungsrichtlinie 2024?"
Ein Standard-LLM würde entweder einen Prozess halluzinieren, zugeben, dass er ihn nicht kennt, oder etwas aus seinen generischen Trainingsdaten ziehen, das nichts mit Ihrer spezifischen Unternehmensrichtlinie zu tun hat.
Ein RAG-gestützter Assistent macht jedoch etwas anderes. Er ruft zunächst die relevantesten Teile Ihrer internen Dokumentation ab - zum Beispiel das PDF Ihrer Beschaffungsrichtlinien - und generiert dann eine präzise, fundierte Antwort auf der Grundlage der abgerufenen Dokumente. Das Modell stellt keine Vermutungen an. Es fasst echte, aktuelle Informationen zusammen, die Sie zur Verfügung gestellt haben.
Das ist der entscheidende Unterschied. Antworten auf der Grundlage von Trainingsdaten = Verallgemeinerung. Antworten aus abgerufenen Dokumenten = Spezifität und Genauigkeit. Für RAG-KI-Anwendungen in Unternehmen ist diese Unterscheidung von entscheidender Bedeutung.
Häufige Unternehmensszenarien, in denen dies von Bedeutung ist, sind unter anderem:
- HR-Teams, die interne Grundsatzdokumente abfragen
- Rechtsteams, die Tausende von Vertragsvorlagen durchsuchen
- Vertriebsteams, die aktuelle Produktspezifikationen und Preislisten abrufen
- Compliance-Teams, die in Echtzeit auf gesetzliche Änderungen zugreifen
Wie Retrieval Augmented Generation funktioniert
Architektur der abruferweiterten Generierung
Das Verständnis der Architektur von Retrieval Augmented Generation ist für jede Führungskraft, die diese Technologie evaluiert oder implementiert, unerlässlich. Das System besteht aus fünf Schlüsselkomponenten, von denen jede eine bestimmte Rolle spielt.
1. Dateneingabe und Dokumentenverarbeitung
Zunächst werden Ihre Wissensquellen - PDFs, Datenbanken, Wikis, E-Mails, Berichte - in das System eingespeist. Diese Dokumente werden bereinigt, in überschaubare Segmente unterteilt und für die Indizierung vorbereitet. Die Qualität dieses Schrittes wirkt sich direkt auf alle nachgelagerten Schritte aus. Garbage in, garbage out ist hier schmerzlich wahr.
2. Modelle einbetten
Als Nächstes wird jedes Textstück in eine numerische Darstellung umgewandelt, die als Einbettung bezeichnet wird. Einbettungen erfassen die semantische Bedeutung des Textes, nicht nur die Schlüsselwörter. Zwei Sätze, die dasselbe bedeuten, haben ähnliche Einbettungen, auch wenn sie unterschiedliche Wörter verwenden. Das macht die semantische Suche so leistungsfähig.
3. Vektorspeicher oder Suchindex
Diese Einbettungen werden in einer Vektordatenbank gespeichert - in speziell entwickelten Systemen wie Pinecone, Weaviate oder pgvector. Wenn ein Benutzer eine Anfrage stellt, wandelt das System diese Anfrage in eine Einbettung um und führt eine Ähnlichkeitssuche durch. Die semantisch relevantesten Dokumentabschnitte werden als Ergebnisse zurückgegeben.
4. Abruf-Pipeline
Die Retrieval-Pipeline orchestriert die Suche. Sie nimmt die Abfrage des Benutzers, erzeugt ihre Einbettung, fragt den Vektorspeicher ab und gibt die Top-N der relevantesten Chunks zurück. Fortgeschrittene Pipelines umfassen Schritte zur Neueinstufung, Metadatenfilterung und hybride Suche (Kombination von Vektor- und Stichwortsuche).
5. Generative Modellantwort
Schließlich wird der gefundene Kontext zusammen mit der ursprünglichen Frage des Benutzers in die Eingabeaufforderung eingefügt. Das LLM generiert dann eine Antwort, die sich auf diesen spezifischen Kontext stützt. Das Modell muss die Antwort nicht aus dem Training "kennen" - es liest sie aus den abgerufenen Chunks und synthetisiert eine Antwort.
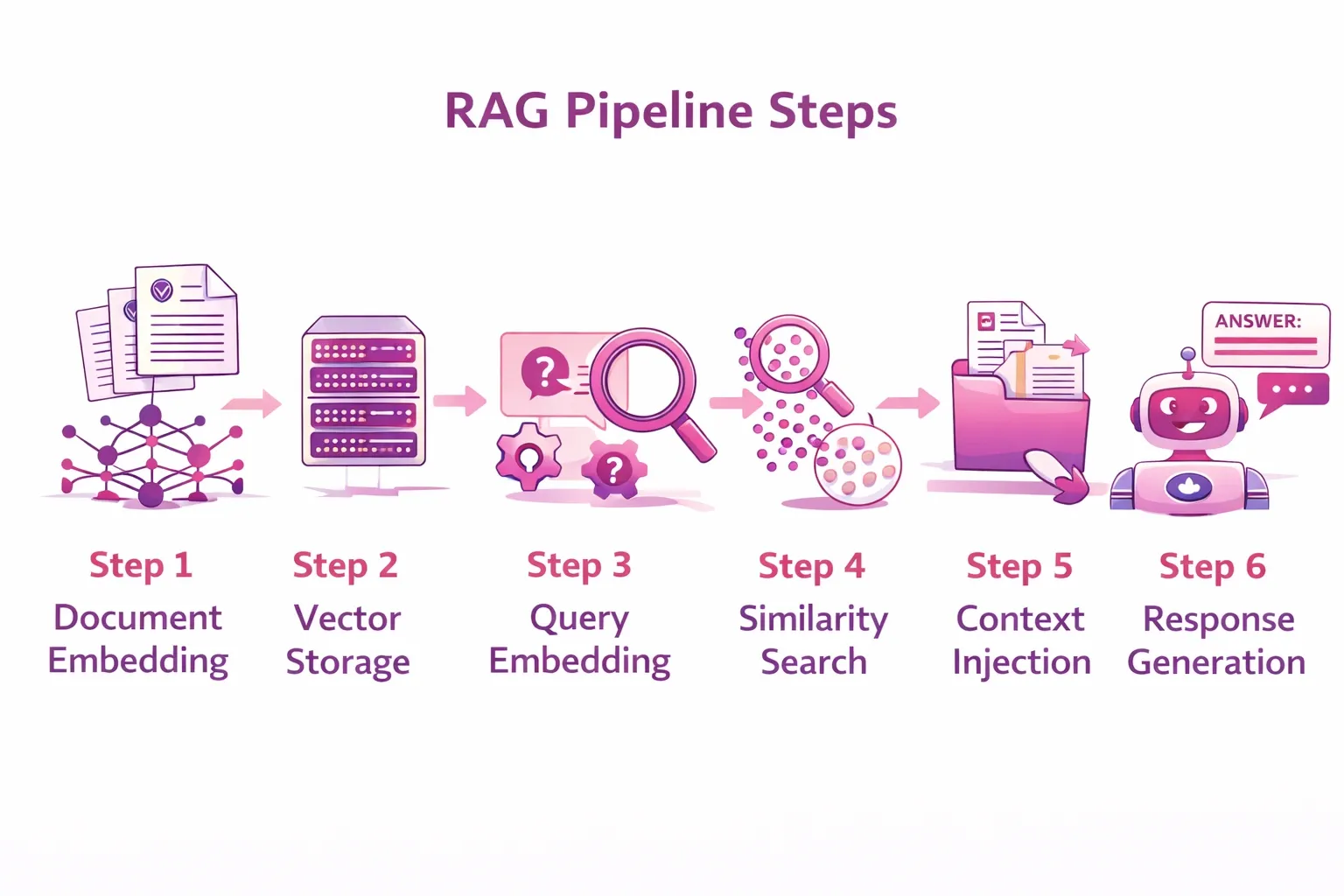
Die RAG-Pipeline Schritt für Schritt
Verfolgen wir nun den gesamten Weg einer einzelnen Anfrage durch ein RAG-System:
- Schritt 1 - Dokumenteneinbettung: Ihre internen Dokumente werden in Chunks zerlegt (z.B. 500 Token pro Chunk) und in Vektoreinbettungen umgewandelt, wobei ein Modell wie text-embedding-ada-002 von OpenAI oder eine selbst gehostete Alternative verwendet wird.
- Schritt 2 - Vektorspeicherung: Diese Einbettungen werden zusammen mit Metadaten wie Dokumententitel, Datum und Quell-URL in einer Vektordatenbank gespeichert.
- Schritt 3 - Einbettung der Abfrage: Wenn ein Benutzer eine Frage stellt, wird diese Frage ebenfalls in eine Einbettung umgewandelt, wobei dasselbe Modell verwendet wird.
- Schritt 4 - Ähnlichkeitssuche: Das System findet die besten Dokumentabschnitte, deren Einbettungen der Einbettung der Anfrage am ähnlichsten sind.
- Schritt 5 - Kontexteinbettung: Die gefundenen Chunks werden als Teil der Eingabeaufforderung an den LLM weitergeleitet: "Basierend auf dem folgenden Kontext: [abgerufenen Chunks], beantworten Sie diese Frage: [Benutzeranfrage]."
- Schritt 6 - Antwortgenerierung: Der LLM generiert eine fundierte, genaue Antwort unter Verwendung des abgerufenen Kontexts.
Laut Gartner werden bis 2026 mehr als 80 % der Unternehmen generative KI-APIs verwenden oder generative KI-fähige Anwendungen in der Produktion einsetzen, und RAG-Architekturen sind zunehmend der Standardansatz für die Verankerung dieser Anwendungen in echten Daten.
RAG vs. Feinabstimmung: Die Wahl des richtigen Ansatzes
Retrieval Augmented Generation vs. Feinabstimmung
Wenn Führungskräfte zum ersten Mal untersuchen, wie sie ein LLM für ihr Unternehmen anpassen können, stehen sie oft vor einer wichtigen Entscheidung: Retrieval Augmented Generation vs. Fine-Tuning. Beide Ansätze haben ihre Berechtigung, aber sie lösen grundlegend unterschiedliche Probleme.
Feinabstimmung bedeutet, ein Basismodell zu nehmen und es auf Ihren eigenen Daten weiter zu trainieren. Dadurch werden die tatsächlichen Gewichte des Modells verändert. Diese Methode ist sehr wirkungsvoll, um dem Modell einen bestimmten Schreibstil, einen bestimmten Tonfall oder ein spezielles Fachvokabular beizubringen. Es ist jedoch teuer, langsam in der Aktualisierung und verhindert keine Halluzinationen bei wirklich neuen Abfragen.
RAG hingegen berührt die Gewichte des Modells überhaupt nicht. Stattdessen werden relevante Informationen zum Zeitpunkt der Inferenz dynamisch abgerufen. Das bedeutet, dass Ihre Wissensdatenbank kontinuierlich aktualisiert werden kann - laden Sie heute ein neues Dokument hoch, und die KI kann morgen Fragen dazu beantworten. Keine Nachschulung erforderlich.
Hier ist ein praktischer Vergleich:
| Aspekt | Fine-Tuning | Retrieval-Augmented Generation (RAG) |
| Kosten | Erfordert erhebliche Rechenressourcen und gekennzeichnete Trainingsdaten. | In der Regel günstiger in Wartung und Aktualisierung. |
| Geschwindigkeit von Updates | Die Aktualisierung des Modells kann Tage oder Wochen dauern, da ein erneutes Training erforderlich ist. | Aktualisierungen der Wissensbasis können innerhalb von Minuten erfolgen, ohne das Modell neu zu trainieren. |
| Transparenz | Intransparent – es ist schwierig nachzuvollziehen, wie das Modell zu einer Antwort gelangt ist. | Transparent – Sie können sehen, welche Dokumente zur Generierung der Antwort abgerufen wurden. |
| Genauigkeit bei aktuellen Daten | Wissen ist zum Zeitpunkt des Trainings eingefroren und kann mit der Zeit veralten. | Sehr gut bei aktuellen Daten, da stets die neuesten Informationen aus der Wissensbasis abgerufen werden. |
| Stilistische Konsistenz | Stark – ideal, wenn ein konsistenter Ton oder Schreibstil erforderlich ist. | Schwächer bei strenger Stilkontrolle, da Antworten vom abgerufenen Inhalt abhängen. |
Für die meisten Anwendungsfälle in Unternehmen, die dynamisches Wissen erfordern - interne Richtlinien, Produktdaten und gesetzliche Aktualisierungen - ist RAG die praktischere und skalierbarere Wahl.
Hybride Ansätze: Das Beste aus beiden Welten
Anspruchsvolle KI-Teams kombinieren in zunehmendem Maße beide Ansätze. Sie stimmen ein Basismodell auf die domänenspezifische Sprache und den Schreibstil ab und legen dann ein RAG-System darüber, um Echtzeitwissen einzubringen. Eine KI für das Gesundheitswesen könnte beispielsweise auf die Konventionen der klinischen Sprache abgestimmt sein, aber RAG verwenden, um die neuesten Datenbanken für Arzneimittelinteraktionen oder klinische Leitlinien abzurufen.
Moderne KI-Frameworks wie LangChain, LlamaIndex und Haystack machen es einfach, diese mehrschichtigen Architekturen aufzubauen. Sie bieten sofort einsatzbereite Komponenten für Vektorspeicher, Retrieval-Pipelines und LLM-Integration, was den technischen Aufwand für Teams, die Retrieval Augmented Generation in der Produktion implementieren, drastisch reduziert.
Anwendungsfälle der Retrieval Augmented Generation in der realen Welt
Wissensassistenten für Unternehmen
Die unmittelbarste und wertvollste Anwendung von RAG-KI-Anwendungen ist der Wissensassistent für Unternehmen. Dabei handelt es sich um KI-Systeme, die Fragen von Mitarbeitern beantworten können, indem sie auf interne Unterlagen zurückgreifen - Personalrichtlinien, IT-Leitfäden, Einführungsunterlagen und Finanzverfahren.
Unternehmen wie Glean und Guru haben ganze Produktlinien um dieses Konzept herum entwickelt. Anstatt dass Mitarbeiter stundenlang in SharePoint, Confluence, Google Drive und E-Mail nach Informationen suchen müssen, kann ein RAG-gestützter Assistent die richtige Antwort in Sekundenschnelle abrufen und zusammenstellen.
Auch die Wissensdatenbanken des Kundensupports profitieren enorm von RAG. Supportmitarbeiter - oder sogar automatisierte Chatbots - können auf Produkthandbücher, Anleitungen zur Fehlerbehebung und den Verlauf von Supporttickets zurückgreifen, um Probleme schneller und genauer zu lösen.
Branchenspezifische KI-Anwendungen
Gesundheitswesen
Im Gesundheitswesen unterstützt RAG Forschungsassistenten, die Klinikern dabei helfen, relevante Studien, Muster in der Patientengeschichte und klinische Protokolle abzurufen. Jüngste Forschungsergebnisse in Nature Digital Medicine unterstreichen, dass KI-gestützte klinische Werkzeuge die Diagnosegenauigkeit erheblich verbessern können, sofern sie auf aktuellen, zuverlässigen Daten beruhen. Retrieval-Augmented Generation (RAG) hat sich als die führende Architektur herauskristallisiert, um diese Grundlage zu schaffen, indem Modelle mit aktuellen medizinischen Datenbanken verbunden werden.
Finanzdienstleistungen
Finanzanalysten nutzen RAG-gestützte Tools zur Abfrage von Ertragsberichten, SEC-Filings, Marktforschung und internen Modellen. Anstatt 200 Seiten eines 10-K-Filings manuell zu lesen, kann ein Analyst ein RAG-System fragen: "Welches sind die drei wichtigsten Risikofaktoren, die in den Ergebnissen des dritten Quartals erwähnt werden?" und erhält in Sekundenschnelle eine fundierte, zitierte Antwort.
Rechtliches
Anwaltskanzleien und Rechtsabteilungen setzen RAG ein, um in der Rechtsprechung, in Vertragssammlungen und in Datenbanken mit Vorschriften zu suchen. Tools wie Harvey AI und CoCounsel von Thomson Reuters helfen Anwälten, Präzedenzfälle zu recherchieren und Dokumente schneller zu verfassen, indem sie die Suchfunktion erweitern. Die Möglichkeit, exakte Quellen zu zitieren, macht RAG jedoch besonders in juristischen Kontexten wichtig, in denen Genauigkeit nicht verhandelbar ist.
Werkzeuge für Entwickler und Ingenieure
Für Entwicklungsteams bietet RAG leistungsstarke Code-Assistenten, die interne Repositories, README-Dateien, API-Dokumentation und Architekturentscheidungsprotokolle durchsuchen können. Anstatt sich auf die allgemeine öffentliche Dokumentation zu verlassen, erhalten Entwickler Antworten, die auf der tatsächlichen Codebasis und den Standards des Unternehmens basieren.
DevOps-Teams nutzen RAG für die Wissensabfrage bei Vorfällen, indem sie relevante Runbooks und Post-Mortems in Echtzeit während eines Ausfalls abrufen. Darüber hinaus verwenden Dokumentations-Automatisierungs-Tools RAG, um internes Wissen zusammenzufassen und in aktualisierten Dokumenten zusammenzufassen, ohne dass die Ingenieure alles manuell schreiben müssen.
Herausforderungen und Best Practices für die Implementierung von RAG
Datenqualität und Abrufgenauigkeit
Das wichtigste Kriterium für eine erfolgreiche RAG-Implementierung ist die Datenqualität. Wenn die zugrundeliegenden Dokumente unordentlich, inkonsistent oder veraltet sind, wird das Abfragesystem Kontext von schlechter Qualität anzeigen, und selbst das beste LLM wird sich schwer tun, aus schlechten Eingaben genaue Antworten zu generieren.
Hier sind die wichtigsten Best Practices, die wir empfehlen:
- Die Chunking-Strategie ist wichtig: Zu große Chunks verwässern die Relevanz, zu kleine Chunks verlieren den Kontext. Experimentieren Sie mit 300-600-Token-Chunks mit überlappenden Fenstern.
- Verschlagwortung von Metadaten: Kennzeichnen Sie jedes Dokumentstück mit Quelle, Datum, Abteilung und Zugriffsebene. Dies ermöglicht eine leistungsstarke gefilterte Suche und erleichtert die Nachvollziehbarkeit.
- Frische der Daten: Erstellen Sie klare Pipelines für die Aktualisierung Ihrer Wissensdatenbank. Veraltete Dokumente sind in wichtigen Bereichen schlimmer als gar keine Dokumente.
- Bewertung des Abrufs: Verwenden Sie Bewertungssysteme wie RAGAS, um die Abrufpräzision, die Wiederauffindbarkeit und die Zuverlässigkeit der generierten Antworten zu messen.

Überlegungen zur Architektur und Infrastruktur
Die Wahl des richtigen KI-Frameworks und der Vektordatenbank ist eine strategische Entscheidung, nicht nur eine technische. Die von Ihnen gewählte Vektordatenbank muss mit Ihrem Datenvolumen und der Abfragehäufigkeit skalieren. Beliebte Optionen sind:
- Pinecone: Vollständig verwaltet, einfach zu skalieren, stark für Produktionsworkloads.
- Weaviate: Open-Source mit umfangreichen Filterfunktionen und Hybrid-Suchunterstützung.
- pgvector: PostgreSQL-Erweiterung - ideal für Teams, die bereits Postgres nutzen und den Ausbau der Infrastruktur minimieren wollen.
- Qdrant: Leistungsstark, quelloffen, stark für komplexe Filteranwendungen.
Über die Datenbank hinaus ist das Latenzmanagement entscheidend. Jede RAG-Abfrage erhöht die Abruflatenz zusätzlich zur LLM-Generierungszeit. Für kundenorientierte Anwendungen muss dieser Kompromiss sorgfältig abgestimmt werden. Caching-Strategien, ANN-Suchalgorithmen (Approximate Nearest Neighbour) und asynchrone Abrufpipelines tragen zur Verringerung der Latenz bei, ohne die Abrufqualität zu beeinträchtigen.
Schließlich ist auch die Überwachung nicht zu vernachlässigen. Implementieren Sie eine Protokollierung sowohl der Abrufergebnisse als auch der generierten Antworten. Verfolgen Sie Metriken wie die Trefferquote beim Abruf, die Zuverlässigkeit der Antworten und die Zufriedenheit der Benutzer. Ohne Einblick in die Leistung des Systems in der Produktion können Sie es nicht systematisch verbessern.
Warum RAG zu einer Standard-KI-Architektur wird
Lassen Sie uns das Gesamtbild betrachten. Wir befinden uns an einem Wendepunkt bei der Einführung von KI in Unternehmen. Laut dem McKinsey-Bericht "2024 State of AI" setzen 65 % der Unternehmen inzwischen regelmäßig generative KI ein. Der Übergang von der Experimentierphase zur Produktion erfordert die Lösung des Zuverlässigkeitsproblems, das die ersten Implementierungen behindert hat.
RAG geht dieses Zuverlässigkeitsproblem direkt an. Es überbrückt die Lücke zwischen statischen KI-Modellen, die auf historischen Daten trainiert wurden, und den dynamischen, sich ständig ändernden Wissensumgebungen, in denen reale Unternehmen arbeiten. Es ermöglicht KI-Systeme, die nicht nur intelligent, sondern auch fundiert, überprüfbar und aktualisierbar sind.
Darüber hinaus bietet die RAG aus Sicht der Governance und Compliance etwas, was reine LLMs nicht können: Nachvollziehbarkeit. Wenn eine KI-Antwort auf ein bestimmtes Dokumentstück mit einer Quellenangabe zurückverfolgt werden kann, können Unternehmen das KI-Verhalten überprüfen und feststellen, wann das System aktualisiert werden muss. Dies ist in regulierten Branchen wie dem Finanzwesen, dem Gesundheitswesen und den Rechtsdiensten von enormer Bedeutung.
Der Blick in die Zukunft zeigt, dass sich die Entwicklung von RAG beschleunigt. Fortschritte wie Agentic RAG - bei dem KI-Agenten autonom entscheiden, welche Tools und Wissensquellen abgefragt werden sollen - erweitern die Möglichkeiten der Architektur erheblich. Multimodale RAG, die nicht nur Text, sondern auch Bilder, Tabellen und strukturierte Daten abrufen, entwickeln sich ebenfalls rasch.
Die Unternehmen, die heute in eine robuste RAG-Infrastruktur investieren, schaffen sich einen dauerhaften Wettbewerbsvorteil. Sie schaffen KI-Systeme, die jedes Mal, wenn sie neues Wissen hinzufügen, intelligenter werden - ohne teure Umschulungszyklen. Und das auf eine Art und Weise, bei der der Mensch die Kontrolle behält, da er genau weiß, was die KI weiß und wo sie es gelernt hat.
Das Wichtigste in Kürze
- Was ist Retrieval Augmented Generation? Es handelt sich um ein KI-Framework, das die Informationsbeschaffung in Echtzeit mit generativen Sprachmodellen kombiniert, um präzise, fundierte Antworten zu geben.
- Warum ist es wichtig? Es beseitigt die wichtigsten Einschränkungen von eigenständigen LLMs: Halluzinationen, veraltetes Wissen und fehlender eigener Kontext.
- Wie funktioniert es? Dokumente werden eingebettet und in einer Vektordatenbank gespeichert. Zum Zeitpunkt der Abfrage werden relevante Teile abgerufen und in die LLM-Eingabeaufforderung eingefügt.
- RAG vs. Feinabstimmung: RAG ist skalierbarer und kostengünstiger für dynamisches Unternehmenswissen. Die Feinabstimmung ist besser für die stilistische oder fachsprachliche Anpassung.
- Auswirkungen in der realen Welt: Vom Gesundheitswesen über das Finanzwesen und die Rechtsabteilung bis hin zu DevOps - RAG-KI-Anwendungen liefern heute in allen Branchen einen messbaren Mehrwert.
Haben Sie dies als nützlich empfunden? Hier ist, was Sie als nächstes tun sollten.
Wenn dieser Artikel Ihnen ein klareres Bild davon vermittelt hat, was Retrieval Augmented Generation ist und wie es sich auf die KI-Strategie Ihres Unternehmens anwenden lässt, würden wir uns freuen, wenn Sie ihn mit anderen teilen. Leiten Sie ihn an einen Kollegen weiter, der KI für Unternehmen evaluiert. Teilen Sie es auf LinkedIn mit Ihrer Sichtweise, wo RAG in Ihrer Branche passt. Mögen Sie es, kommentieren Sie es und beginnen Sie eine Diskussion.
Je mehr Führungskräfte diese grundlegenden KI-Architekturen verstehen, desto besser sind die Entscheidungen, die Unternehmen beim Einsatz von KI in der Produktion treffen. Helfen Sie uns also, das Wissen zu verbreiten. Ihr Beitrag könnte der Anstoß sein, den jemand in Ihrem Netzwerk braucht, um KI-Systeme zu entwickeln, die tatsächlich funktionieren.